Logging in/Resources¶
Login takes place via the Jupyter URL for the individual HPC service:
-
HoreKa: https://hk-jupyter.scc.kit.edu
-
HAICORE: https://haicore-jupyter.scc.kit.edu
-
bwUnicluster 3.0: https://uc3-jupyter.scc.kit.edu
For login, your username, service password and a 2-factor authentication are required.
You will first find yourself on a landing page that also gives more information about the currently installed software versions.
By pressing the login button you will be redirected to the JupyterHub page. Click on Enter JupyterHub to start the login process. Select the organization (e.g. KIT) that has granted you access to the HPC system and press Continue. In the Login section that appears, enter your username and password (not the HPC service password).
After pressing the Login button you will be redirected to the Second Factor query page. Enter the One-Time Password and click on Validate. Now you are done with the login process and can start selecting your computing resources.
Selection of the compute resources¶
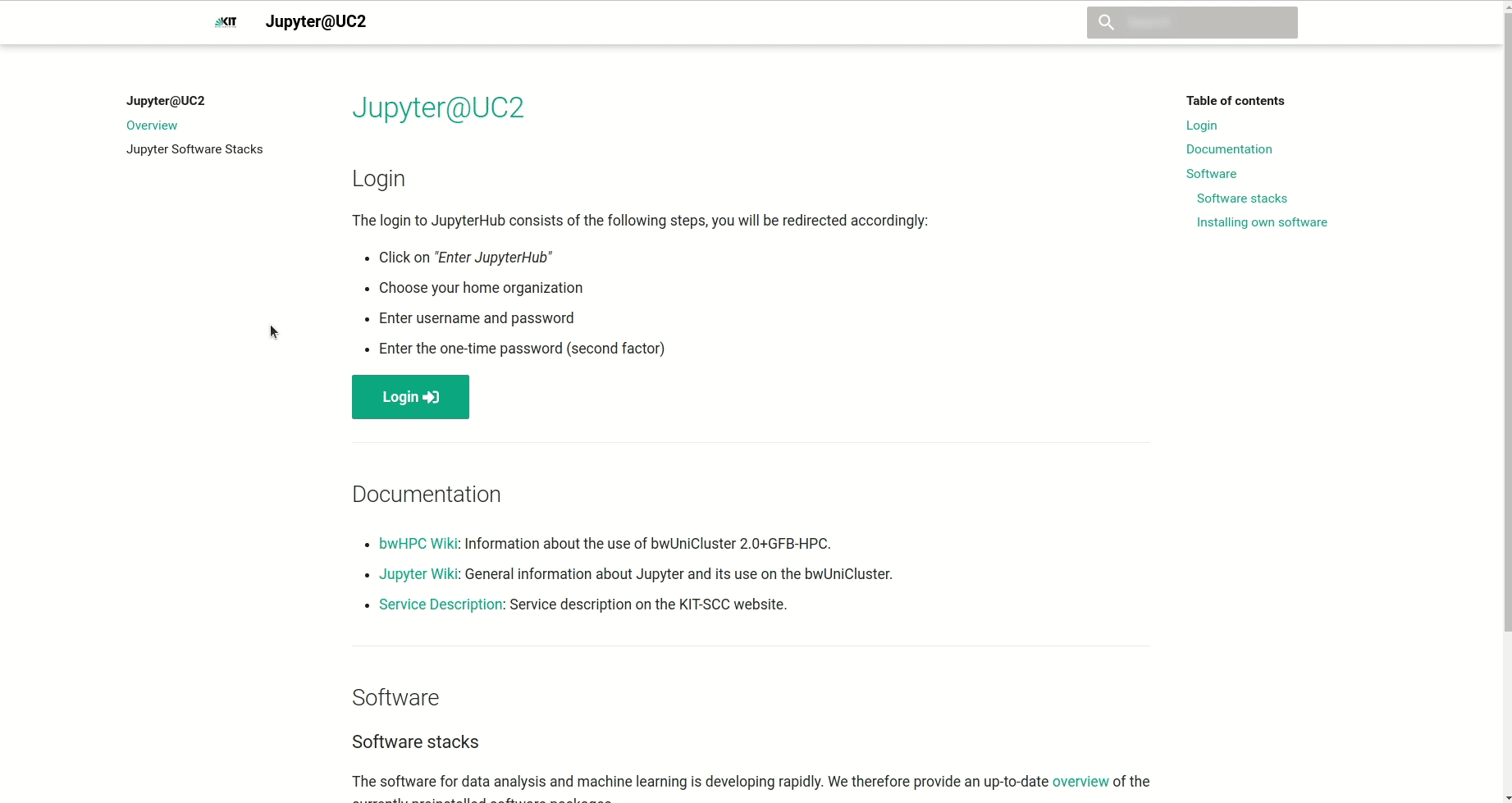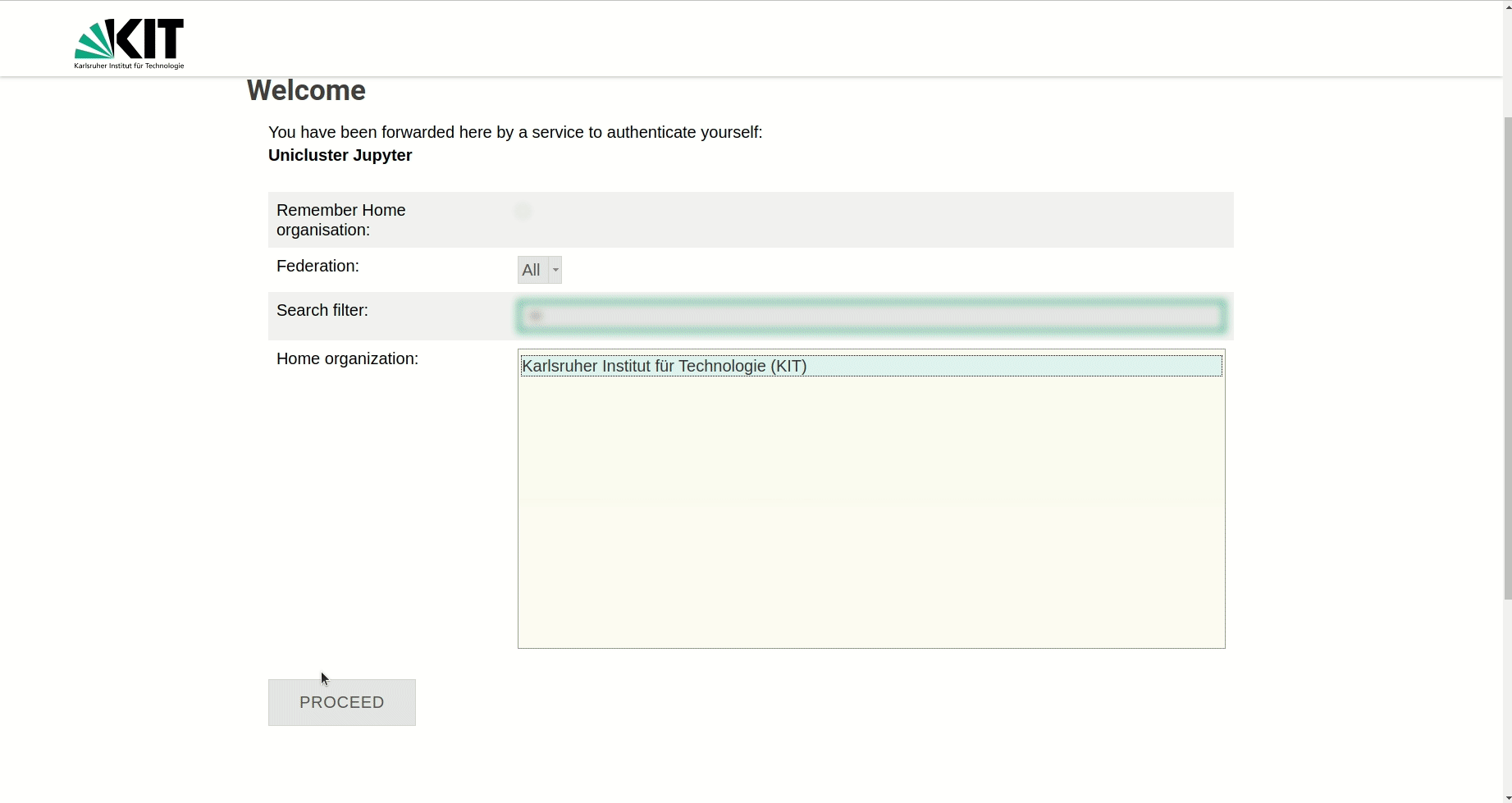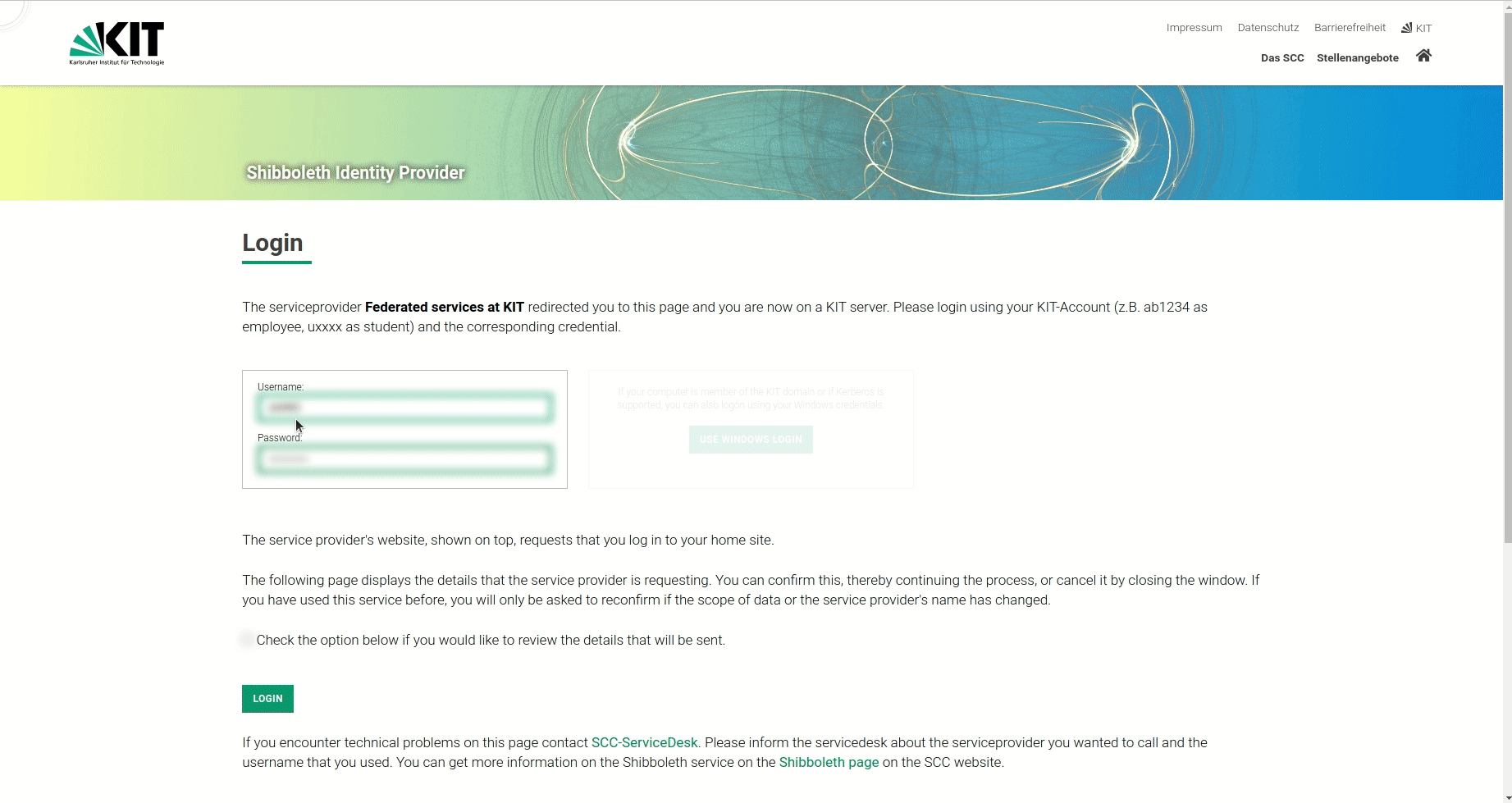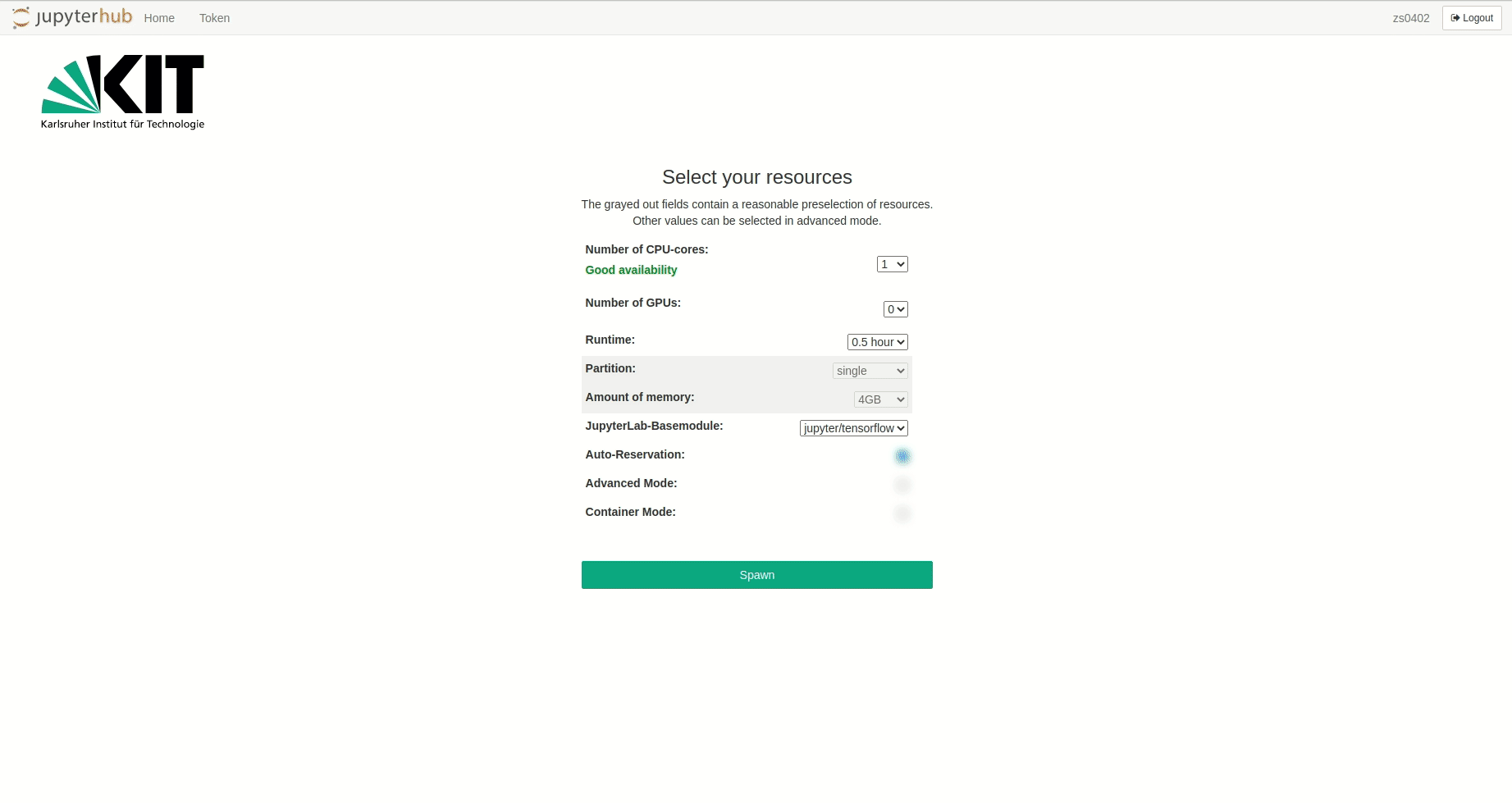
Jupyter notebooks are executed in an interactive session on the compute nodes of the HPC clusters. Just like when accessing an interactive session with SSH, resource allocation is managed by the Slurm workload manager system. The selection of resources for Jupyter is possible using drop-down menus. Jupyter jobs can currently only run on a single node.
Available resources for selection are:
Number of CPU cores
Total number of processes. Corresponds to the sbatch command --cpus-per-task=
Number of GPUs
Corresponds to the sbatch command --gres=gpu:
Runtime
Wall clock time limit. Corresponds to the sbatch command --time=
Partition/Queue
Request a specific queue for the resource allocation. Corresponds to the sbatch command --partition=
Amount of main memory
Memory in Megabyte per node. Corresponds to the sbatch command --mem=
Jupyter base module
The initial Jupyter environment to load on startup. Corresponds to the Lmod command module add
If Auto-Reservation is selected the automatic Jupyter reservation of the cluster is enabled.
With Container Mode Docker containers can be used instead of Lmod Jupyter environments. For further information click here.
In Normal Mode, the grayed-out fields contain reasonable presets depending on the number of required CPU cores or GPUs selected. The presects can be bypassed in Advanced Mode, where further options are available.
Advanced Mode can be activated by clicking on the checkbox of the same name. The following additional options then become available:
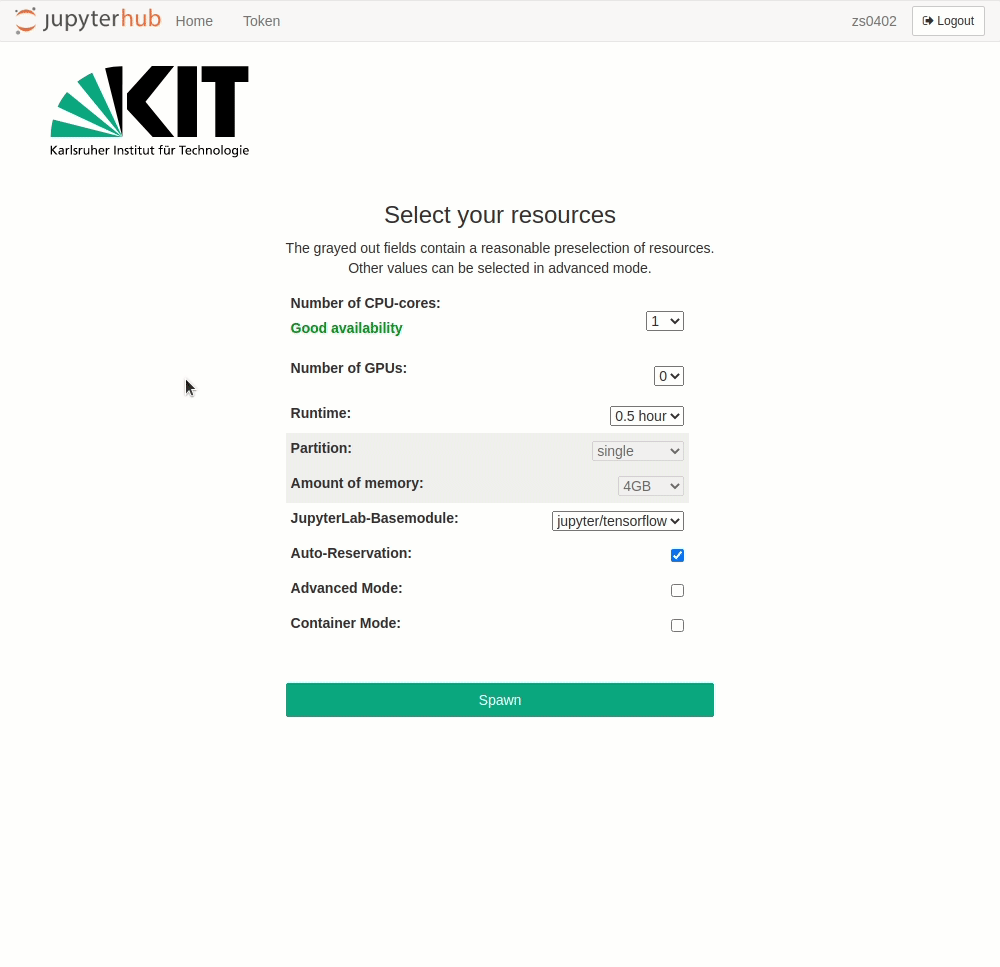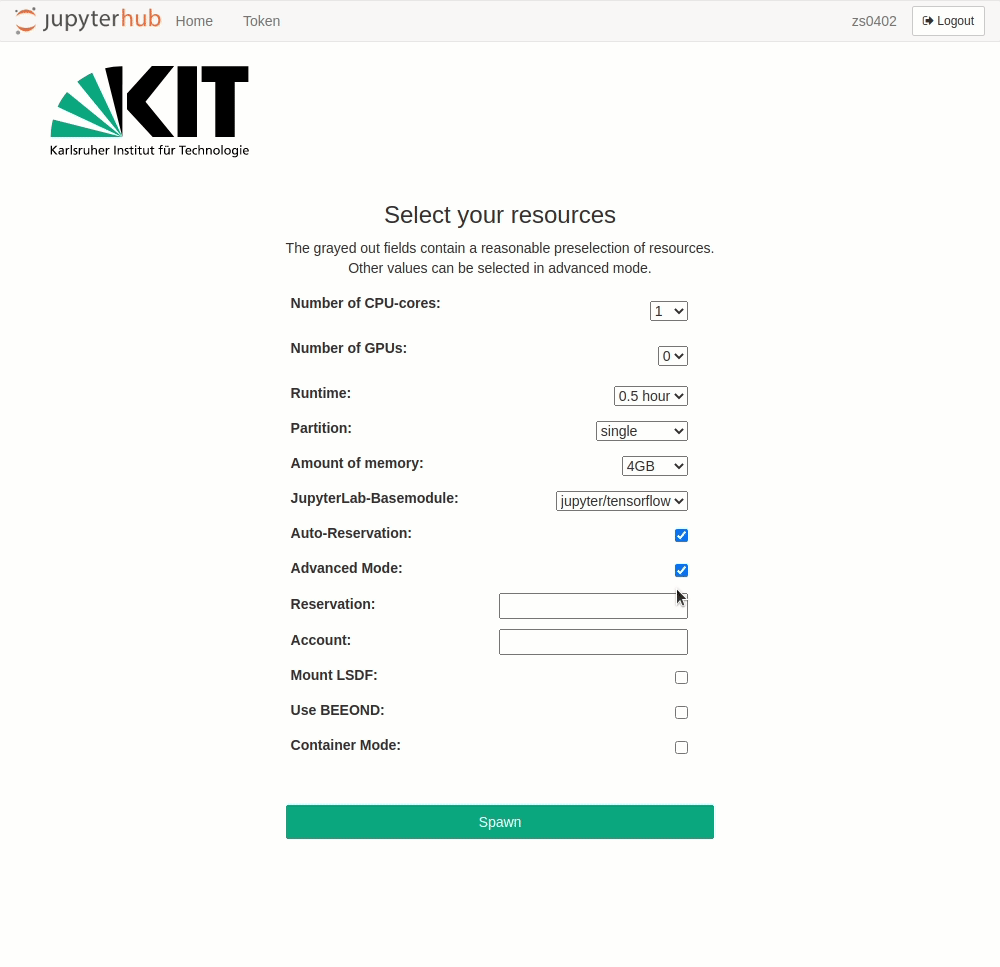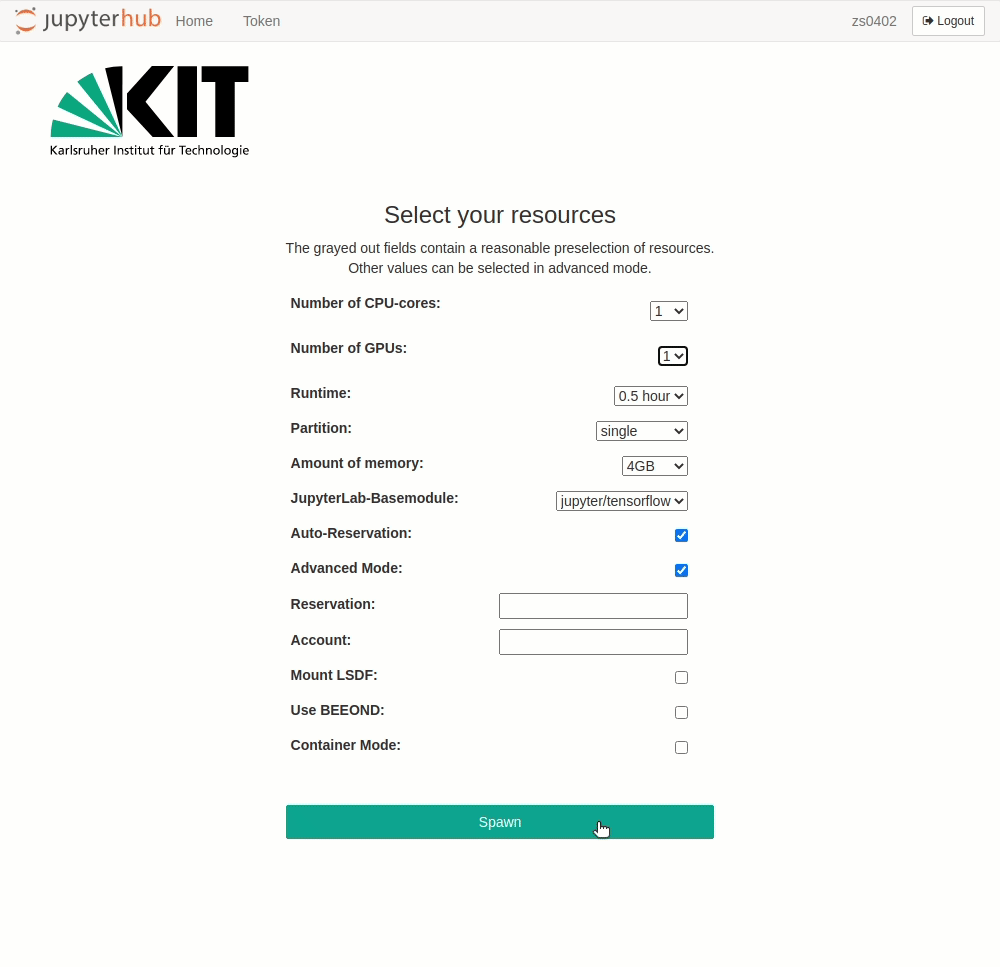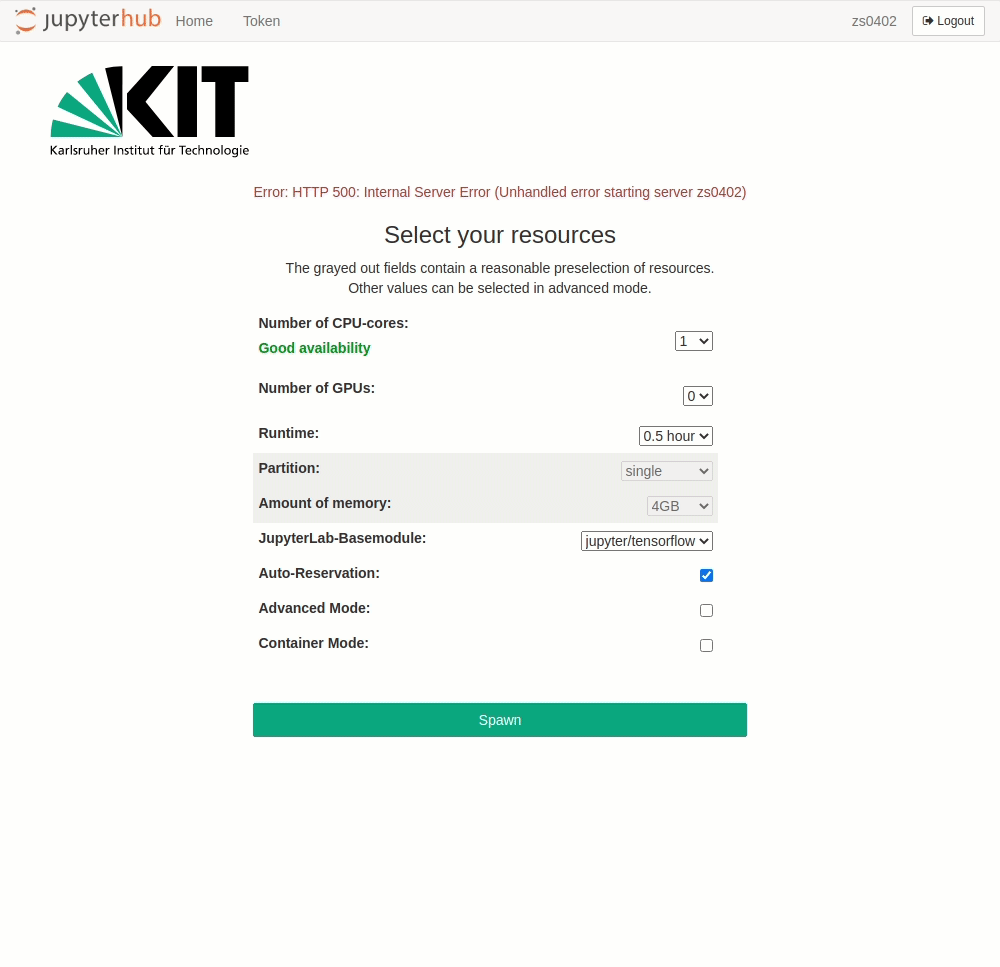
- Specification of a reservation
- Selection of an account, if one is a member of several projects
- LSDF mount option
- BEEOND mount option
After the selection is made, the interactive job is started with the Spawn button. As when requesting interactive compute resources with the salloc command, waiting times may occur. These are usually the longer the larger the requested resources are. Even if the chosen resources are available immediately, the spawning process may take up to one minute.
Please note that in advanced mode, resource combinations can be selected that are impossible to be met. In this case, an error message will appear when the job is spawned.
The spawning timeout is currently set to 10 minutes. With a normal workload of the HPC facility, this time is usually sufficient to get interactive resources.
Prioritized access to computing resources on bwUnicluster 3.0¶
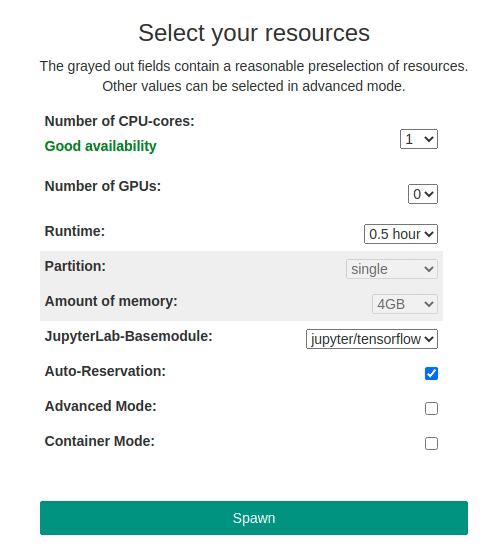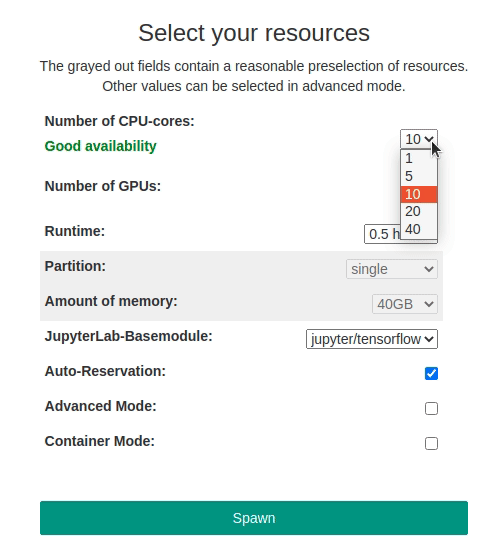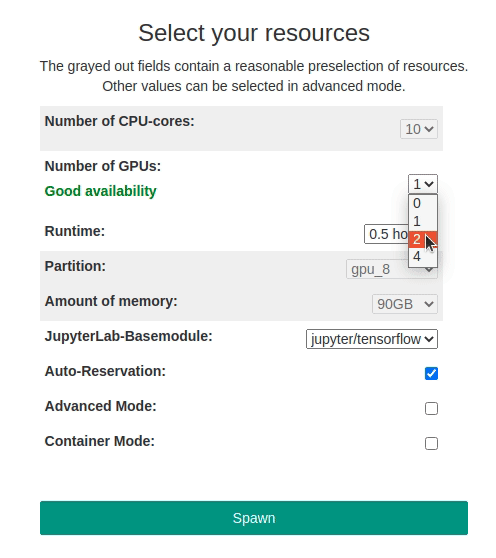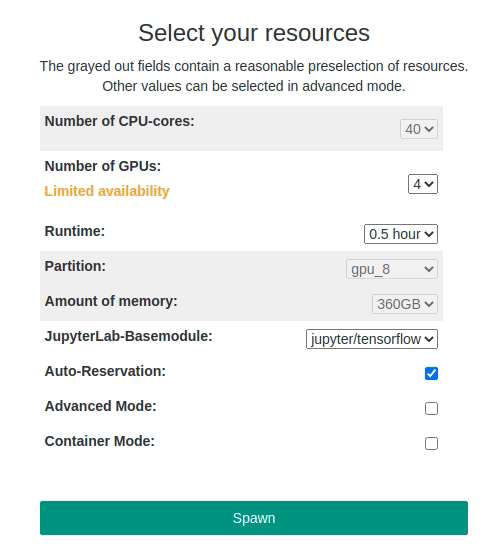
The use of Jupyter requires the immediate availability of computing resources since the JupyterLab server is started within an interactive Slurm session. To improve the availability of Resources for interactive supercomputing with Jupyter, automatic reservation for CPU and GPU (gpu_8) resources has been set up on bwUnicluster 3.0. It is active between 8am and 8pm every day. The reservation is automatically active if:
- no other reservation is set manually
- Auto-Reservation is enabled
To give you a better overview of the currently available resources, a status indicator has been implemented. It appears when selecting the number of required CPUs/GPUs and shows whether a Jupyter job of the selected size can currently be started or not. Green means the selected CPU/GPU resources are available instantly. Yellow means only a single additonal job of the selected size can be started. Red means there are no CPU/GPU resources left that could satisfy the selected amount of resources.
If there are no more resources available within the reservation, you can try selecting a different amount of CPUs/GPUs or activate Advanced Mode and select a different partition. Availability can be estimated using sinfo_t_idle, which is available when logging in via SSH.