JobMon - Job Performance Metrics¶
JobMon helps you answer common performance questions such as:
- Why is my job so slow, and what could be the bottleneck?
- Did my optimization improve performance?
- Is the limiting factor the application, or the cluster hardware?
- Am I fully utilizing the resources I requested?
What is JobMon?¶
JobMon is a web-based service for job performance analysis on HoreKa. It visualizes selected performance metrics collected on compute nodes while your job is running. No manual instrumentation is required.
JobMon stores metrics long enough to compare runs over time and validate optimization steps.
Accessing JobMon¶
JobMon is available to HoreKa users. Login requires authentication via the FeLS service. After authentication you will be redirected to the JobMon welcome page.
Login and Welcome pages

Log in via:
- FeLS authentication
- Local account

You will typically find:
- User information
- Job statistics: number of jobs in the last week, number of finished jobs, number of running jobs
Data retention policy¶
Metrics are retained for 4 weeks. Only jobs within this time window are visible in JobMon.
Privacy model¶
Users can only view metrics for their own jobs. Administrators have additional privileges (e.g., viewing all jobs, applying system-wide tags, viewing system-wide metrics and statistics).
Analyzing jobs¶
Job performance commonly falls into one (or more) of the following categories:
- Compute bound: CPU/GPU compute throughput is the limiting factor.
- Memory bound: Memory bandwidth or latency is the limiting factor.
- Communication bound: Node-to-node communication is the limiting factor.
- I/O bound: Filesystem throughput or metadata performance is the limiting factor.
Jobs are often mixed
Many real workloads alternate between phases (e.g., compute → communication → I/O checkpoint). Use the per-job time series to isolate the steady-state region of each phase.
What to look for in JobMon¶
Compute bound¶
- Typical signals: high CPU FLOP/s and/or high GPU utilization; IPC often relatively high; memory bandwidth may be moderate.
- Where to confirm: Performance (FLOP/s, IPC, GPU utilization), optionally Memory for context.
Memory bound¶
- Typical signals: CPU memory bandwidth near peak while FLOP/s and IPC remain comparatively low; on GPUs, high memory utilization / sustained memory activity with less-than-expected compute utilization.
- Where to confirm: Memory (CPU bandwidth, GPU memory utilization), then Performance (IPC/FLOP/s) to see under-utilized compute.
Communication bound¶
- Typical signals: elevated InfiniBand traffic and/or packet rate; performance changes with communication phases; sometimes lower CPU/GPU utilization while communication is dominant.
- Where to confirm: Interconnect (send/receive bandwidth and packets), then correlate with Performance.
I/O bound¶
- Typical signals: filesystem throughput spikes and/or high metadata operation rates; during I/O phases CPU/GPU utilization often drops; checkpointing appears as periodic bursts.
- Where to confirm: Filesystem (throughput and metadata metrics), correlate with Performance.
To illustrate these patterns, the next sections use representative benchmarks.
Compute bound¶
Performance is limited by CPU and/or GPU compute throughput (typically floating point operations). Benchmarks from this category include:
-
DGEMM performs a matrix–matrix multiplication
C = A · B. Forn×nmatrices, it requiresO(n^3)compute operations but onlyO(n^2)memory operations. CPU and GPU implementations exist.Characteristics
- High CPU FLOP/s (CPU run) or high GPU utilization (GPU run)
- Moderate CPU memory bandwidth usage compared to compute saturation
Memory bound¶
Performance is limited by the main memory subsystem (bandwidth and/or latency). Benchmarks from this category include:
-
STREAM performs four kernels: copy (
c=a), scale (b=α·c), add (c=a+b), and triad (a=b+α·c). It stresses memory bandwidth heavily. For n-dimensional vectors computation requiresO(n)memory operations but onlyO(n)compute operations. There are implementations for CPU and GPU available for this benchmark.Characteristics
- CPU memory bandwidth near peak (CPU STREAM)
- GPU memory utilization near saturation (BabelStream on GPU)
- Compute metrics (FLOP/s, IPC) typically very low.
-
High Performance Conjugate Gradients (HPCG)
HPCG runs conjugate gradients on a sparse matrix and is commonly used as a proxy for memory-bound, irregular access patterns. CPU and GPU implementations exist.
Characteristics
- Sustained memory pressure over time
- Often clear phase behavior (setup vs solve), depending on implementation
Communication bound¶
Performance is limited by the interconnect (bandwidth and/or latency). Benchmarks from this category include:
-
OMB performs point-to-point communication with messages of increasing size to measure bandwidth and latency (CPU and GPU variants exist).
Characteristics
- InfiniBand send/receive bandwidth and packet rate rising with message size
- Visible “steps” when the message size changes
I/O bound¶
Performance is limited by filesystem throughput and/or metadata operations. These cases are common in checkpointing, heavy file-per-rank workloads, and metadata-intensive pipelines.
Benchmarks from this category include:
-
Characteristics
- IOR: sustained or bursty read/write throughput; periodic spikes are typical for checkpoint patterns
Jobs page¶
This page presents an overview of your recent batch jobs on HoreKa. Jobs can be filtered by:
- partition
- exit codes
- number of nodes / number of GPUs
- job status (finished/running/all)
- time range (e.g., last week)
- tags (e.g.,
baseline,optA,optB)
The filtered jobs can be sorted by:
- job length
- number of nodes
- start time
- stop time
- job ID

Each job displayed in Jobs page is represented with its meta-data and the so-called spider plot. This plot very easily shows the performance limitations of this job and allows categorization as memory bound, compute bound, or communication bound. For this purpose, the plot shows the average and maximum values for the metrics:
- CPU floating point operations per second
- CPU memory bandwidth
- GPU utilization
- GPU memory utilization
- InfiniBand bandwidth
Examples: Spider Plot
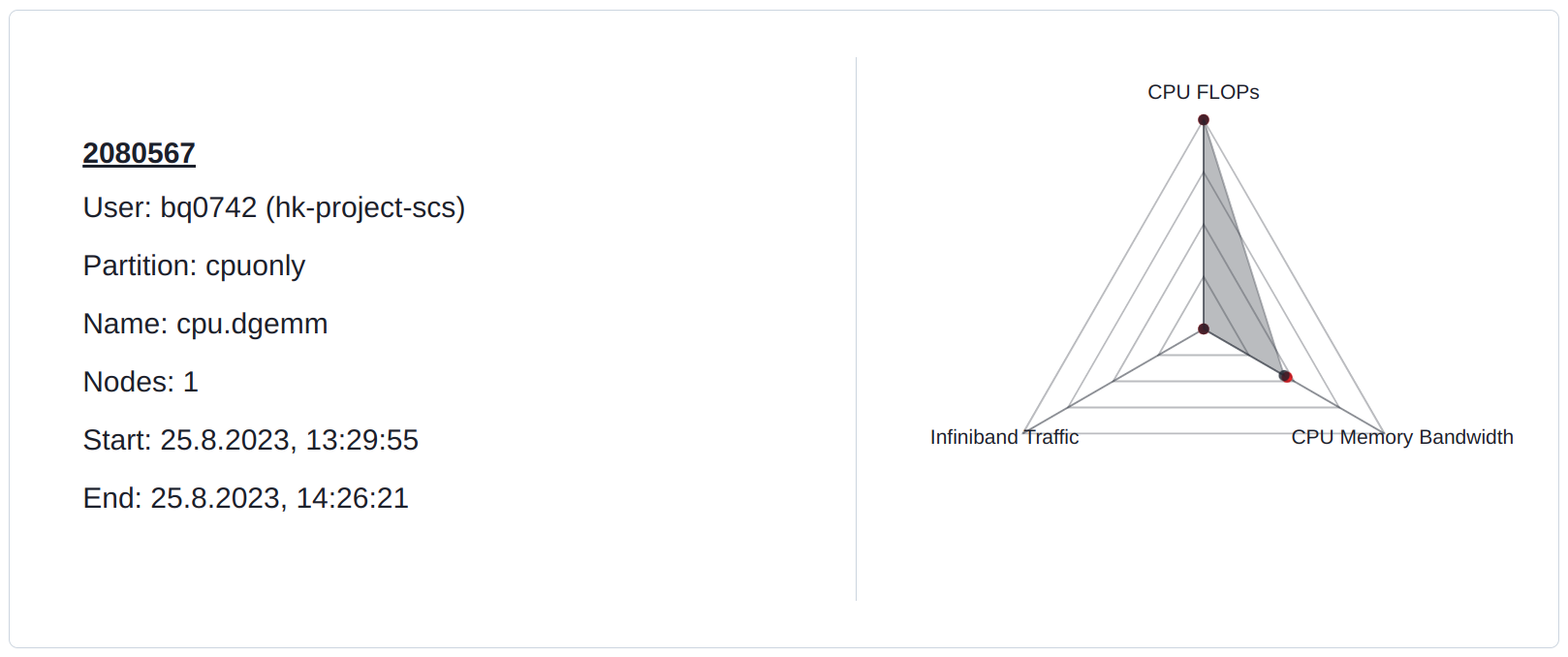
DGEMM is capable of using the entire available floating point power of the node. This also uses a significant portion of the memory bandwidth.
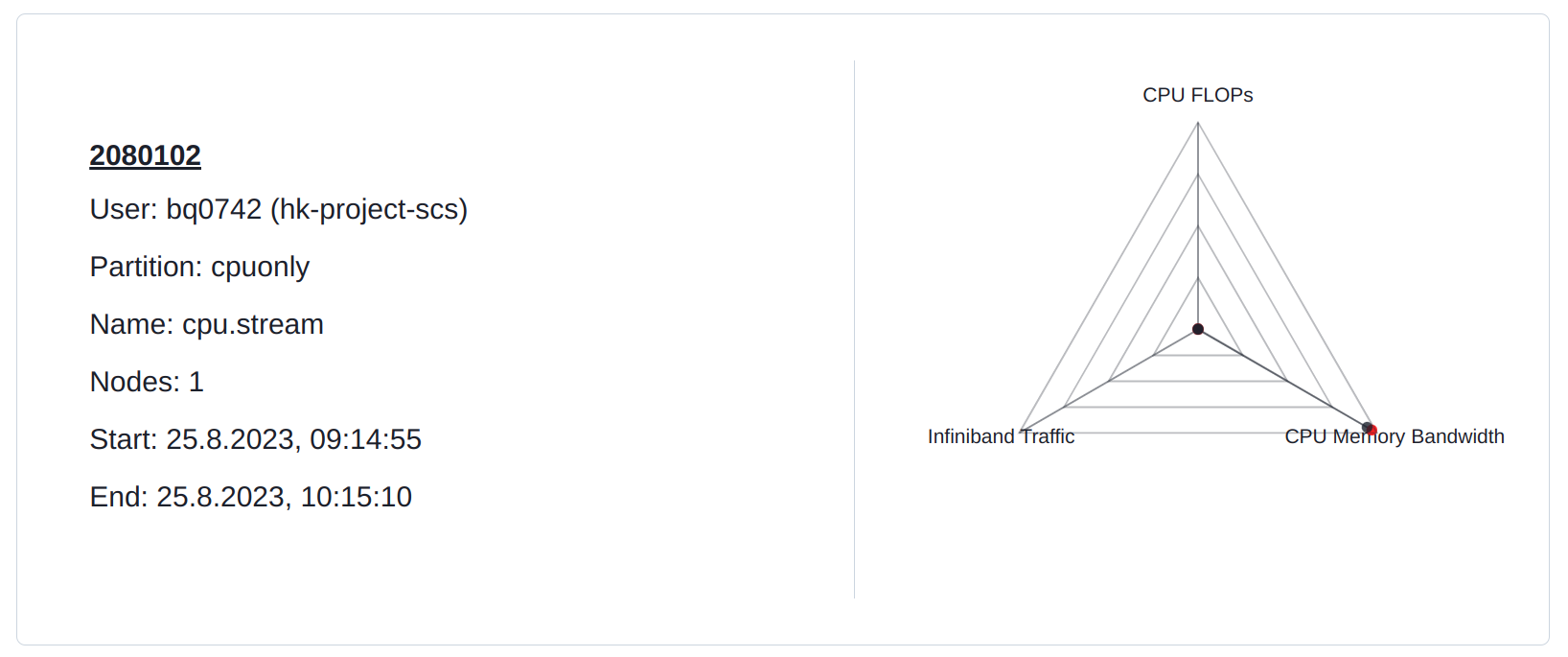
Stream saturates the entire memory bandwidth. All other resources are under-utilized.
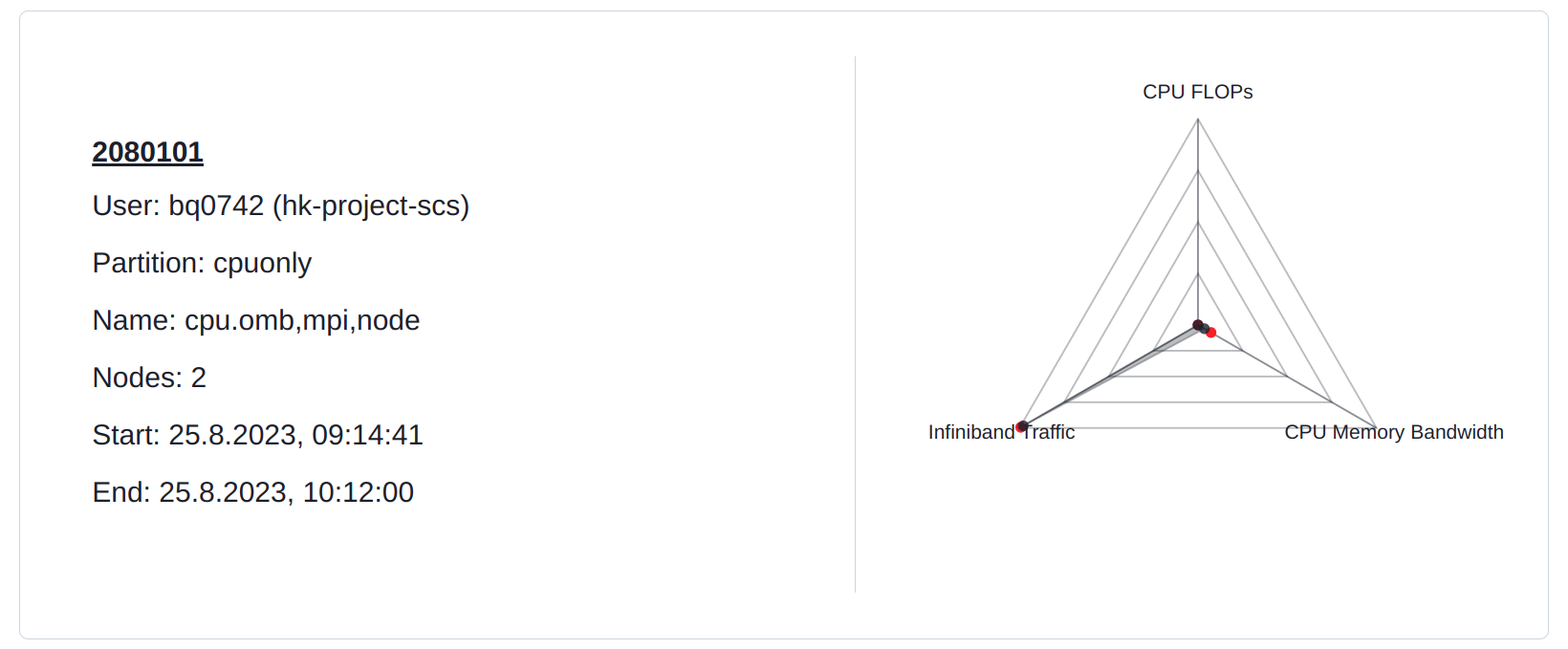
OSU Micro-Benchmarks saturates the entire InfiniBand bandwidth. Some memory bandwidth utilization can also be seen as messages are transferred from memory to memory.
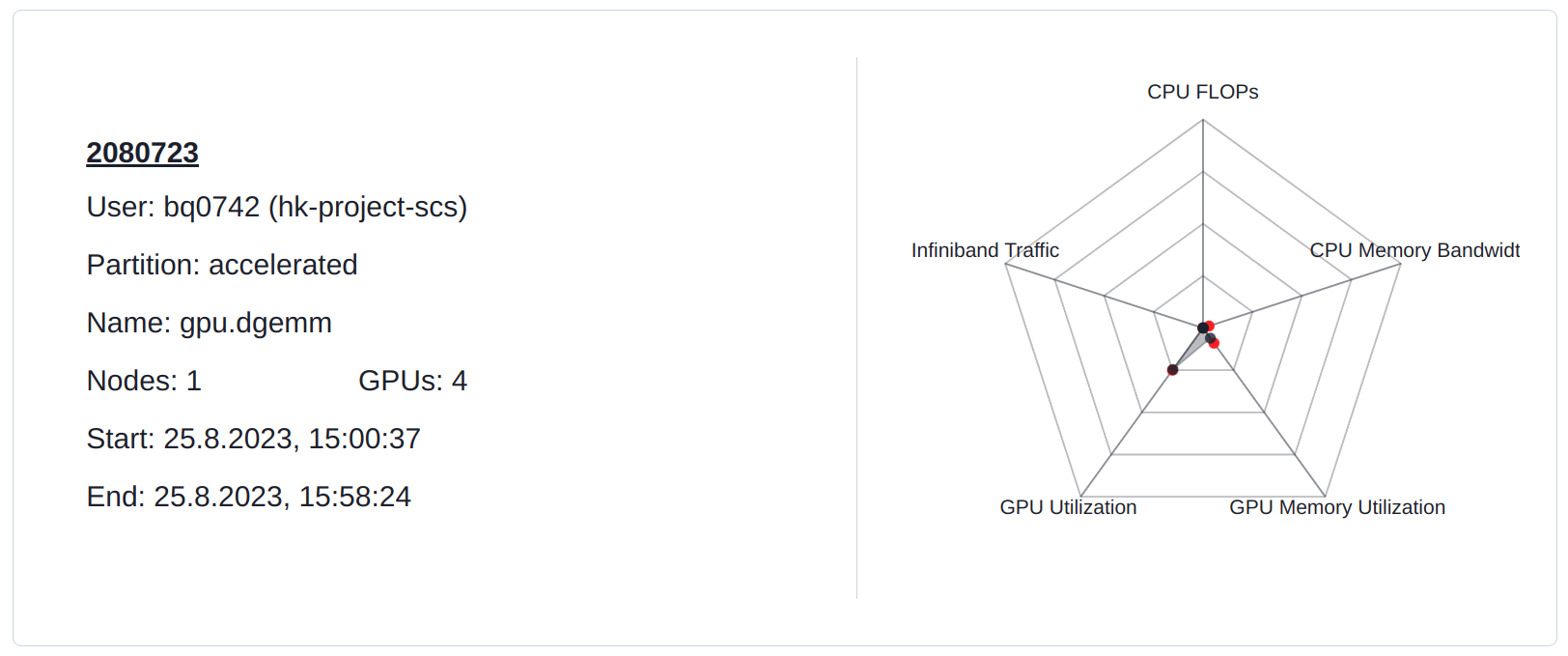
The DGEMM implementation uses only a single GPU. Therefore, only a quarter of the available floating point performance of the GPUs is utilized. This is reflected in the use of memory bandwidth as well.
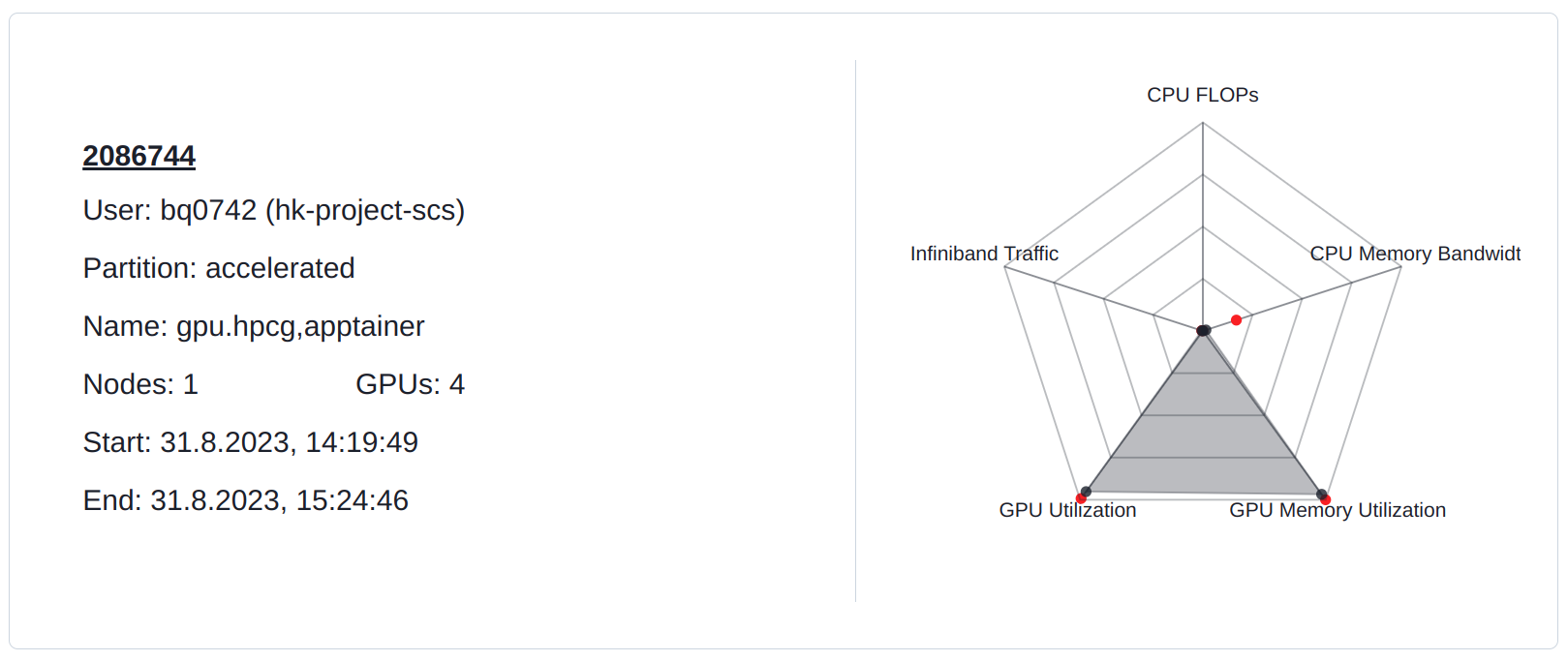
HPCG runs distributed on all GPUs of the node. HPCG saturates the entire memory bandwidth of these GPUs. The compute units are also well utilized.
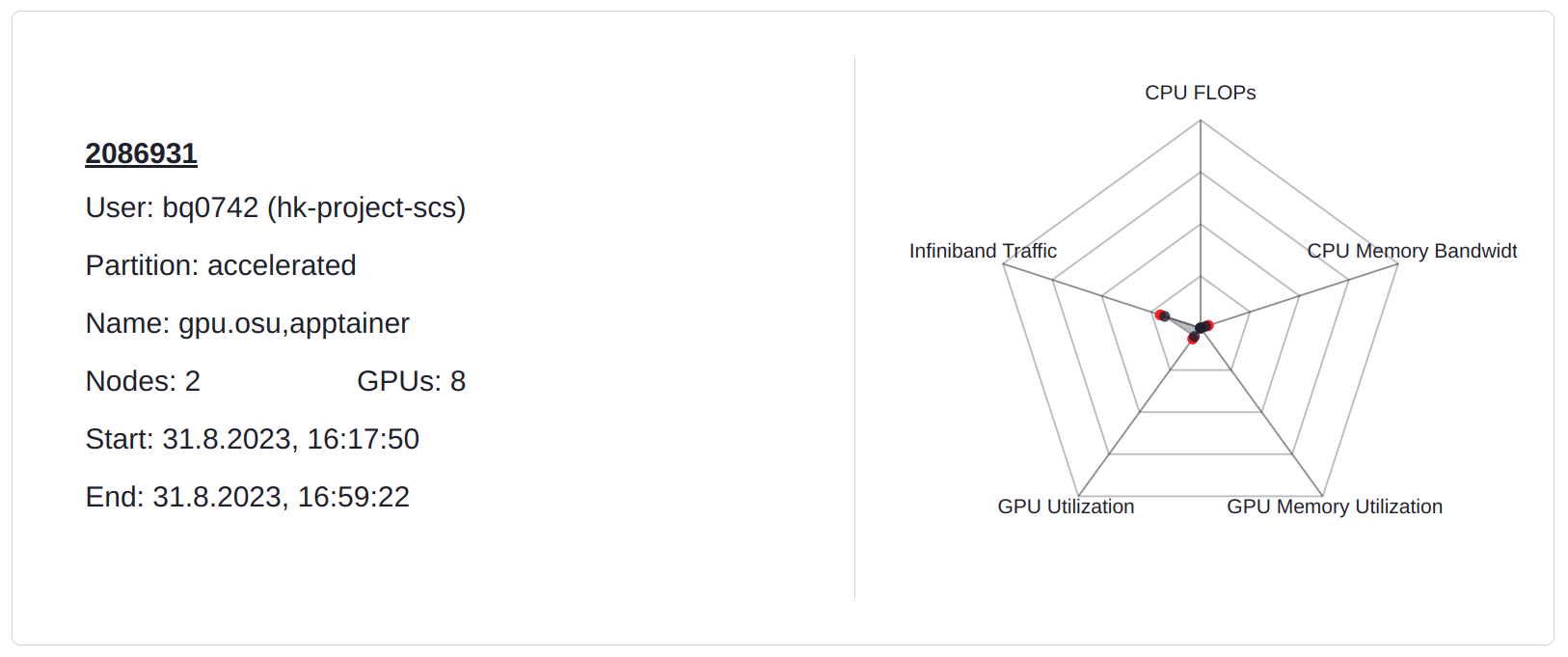
InfiniBand communication between GPUs is not as performant as between CPUs. Therefore, OSU Micro-Benchmarks cannot utilize the entire available InfiniBand bandwidth.
Spider plot
It might happen that the Job analysis failed, as a result the spider plot doesn't represent correctly the given job. In such cases, an empty or a spider plot with missing axes will be shown.
Per-job page¶
Configuration options¶
- Nodes filtering: Show only nodes of interest
- Metrics filtering: Show only selected metrics.
- Time range selection: Select globally a specific time range using the range slider.
-
Tag modification
Tags are a handy tool to mark jobs during different optimization steps (e.g. tags: "without optimization", "optimization A", "optimization B", ...) or jobs from different workflows (e.g. tags: "workflow A", "workflow B"). Filtering for tags on the jobs page allows easily finding all jobs with the same tag.
-
Set sample rate
For longer jobs different sample rates are available.
-
Toggle for Automatic Scaling:
Select diagram y-axis upper and lower limits depending on the measured metric values * Toggle for Changepoints
Change point detection tries to identify times where performance metric behavior changes. If changes are identified, they are displayed as a vertical line in the diagram.
-
Toggle for Quantile view
- Quantile view is a useful feature to improve clarity when too many graphs are displayed in one diagram.
- Information is condensed into only three graphs (25% / 50% / 75% Quantile = Quartiles)
- The 25% Quantile is the graph for which 25% of the measured values are below the graph
- The 50% Quantile is also known as median
- The difference between upper and lower Quantile is a measure for the spread of the metrics
Examples: Quantile View
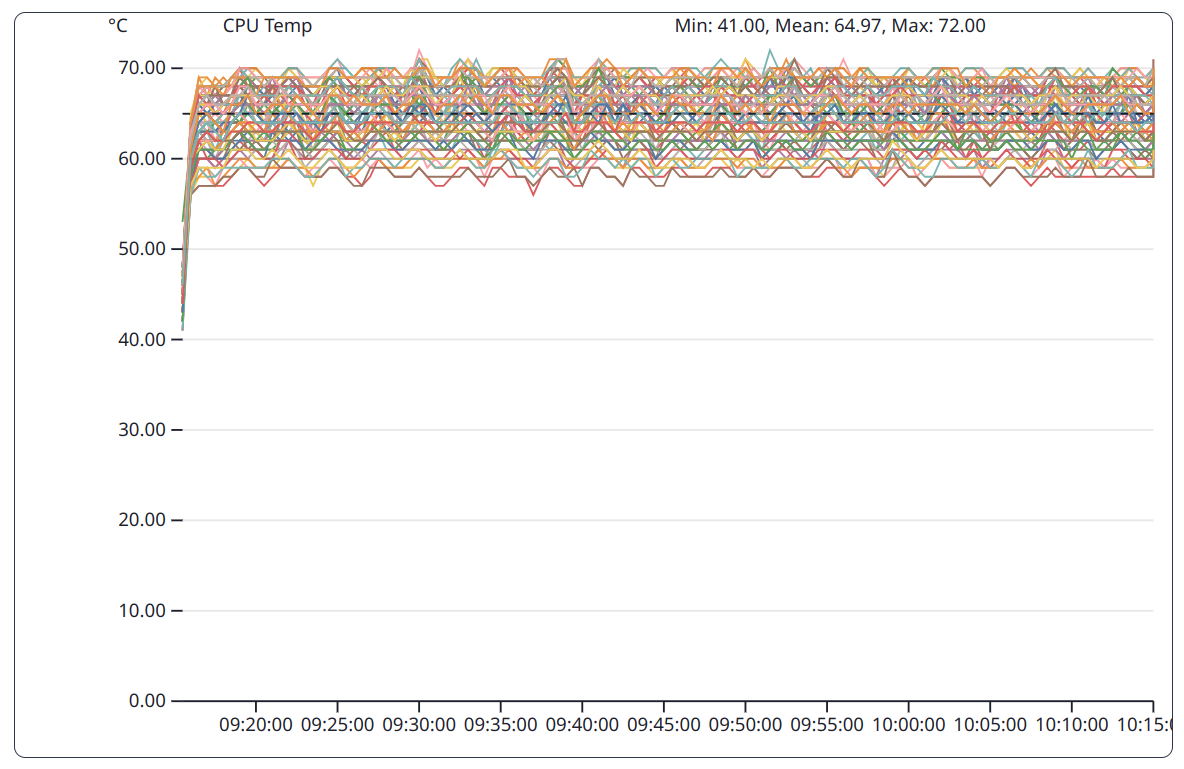
The CPU temperatures are collected per hardware thread, therefore the diagram appears very cluttered
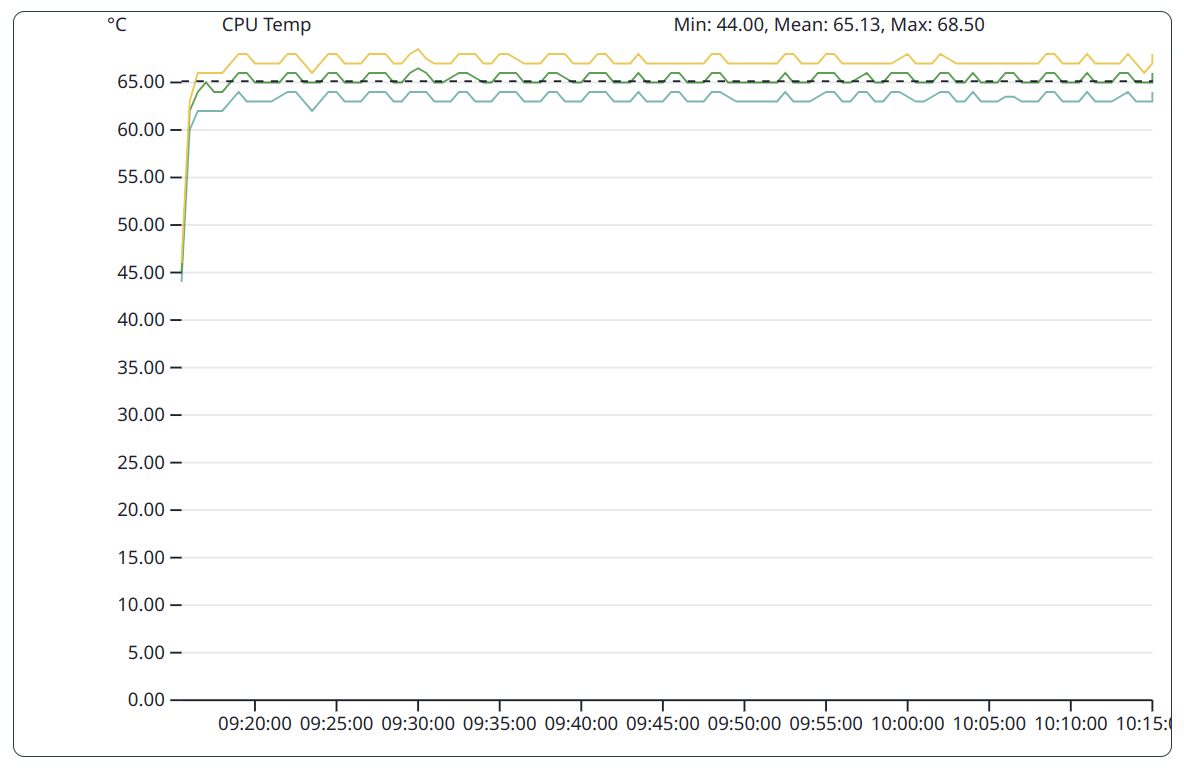
The Quantile View shows the distribution of the CPU temperatures much clearer
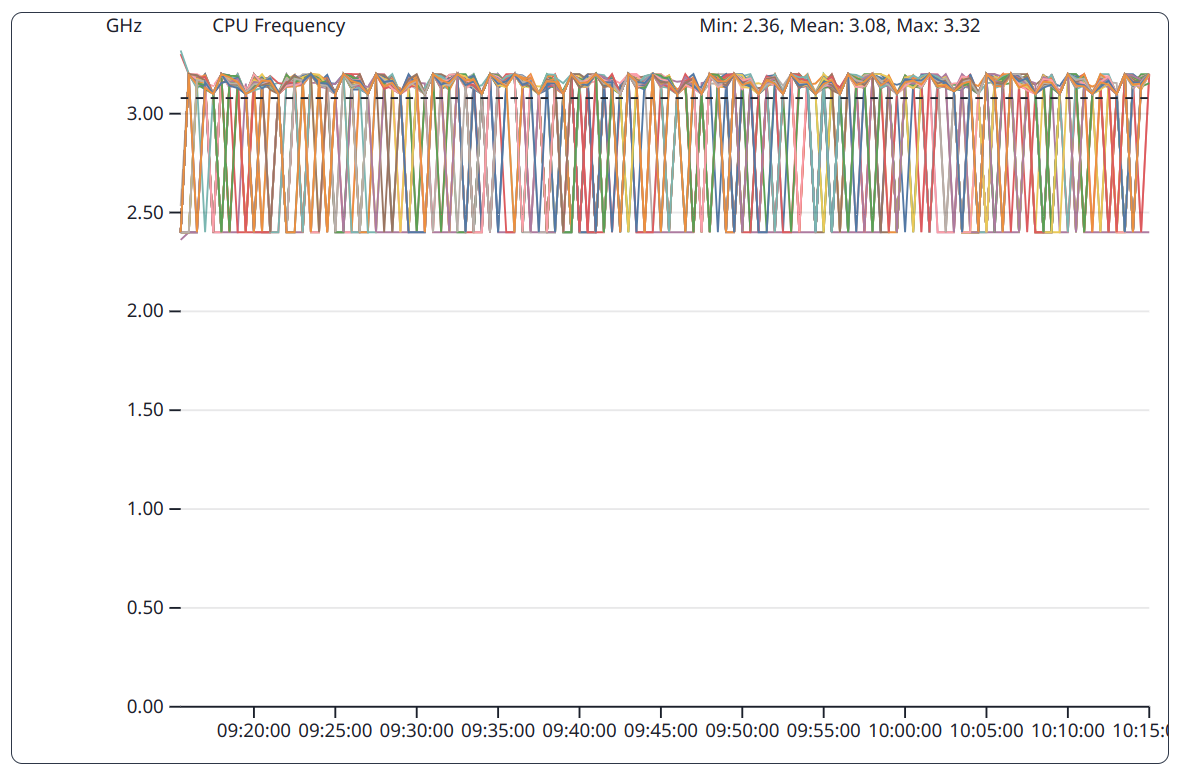
The CPU frequencies are collected per CPU core, therefore the diagram appears very cluttered
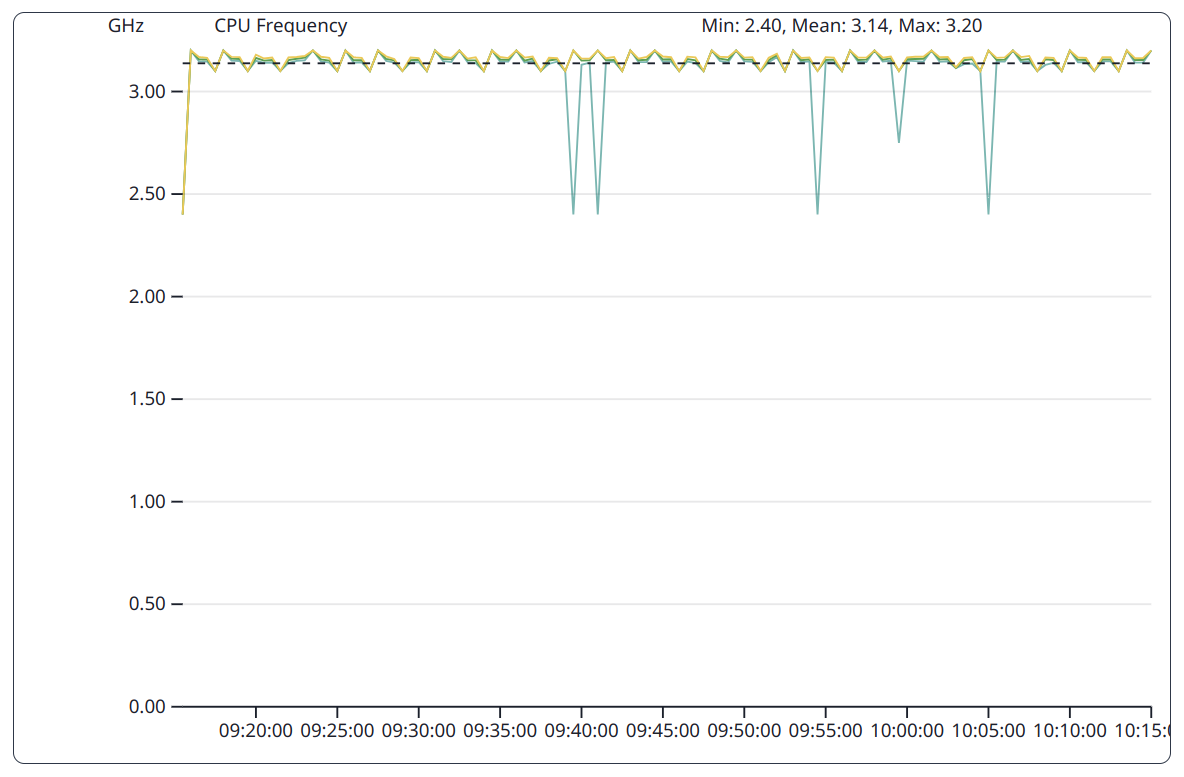
The Quantile View shows the distribution of the CPU frequencies much clearer
Performance categories¶
Metrics are grouped into different categories
Energy¶
This category offers diagrams for:
- CPU power consumption of DRAM channels and the package
- GPU power consumption
- Server system power consumption
Examples: Category Energy
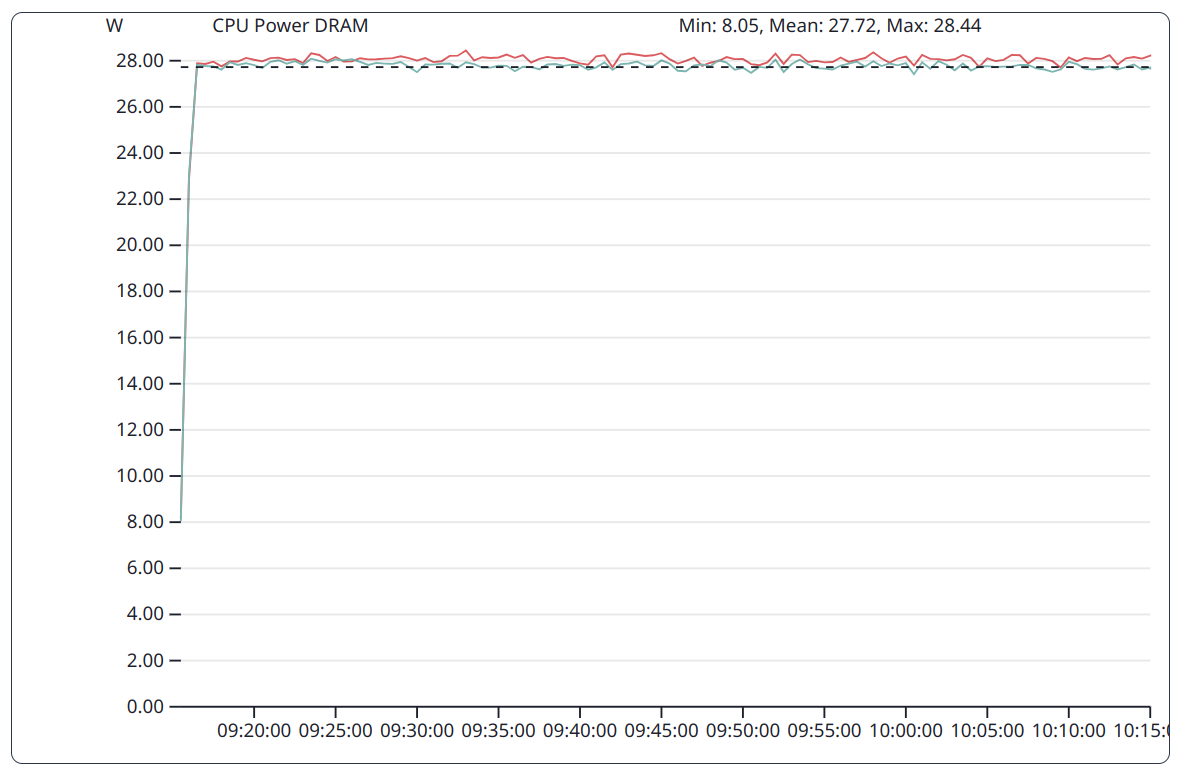
Stream as a memory bound benchmark put constantly high pressure on the DRAM subsystem. This is reflected by a constantly high energy consumption of this subsystem.
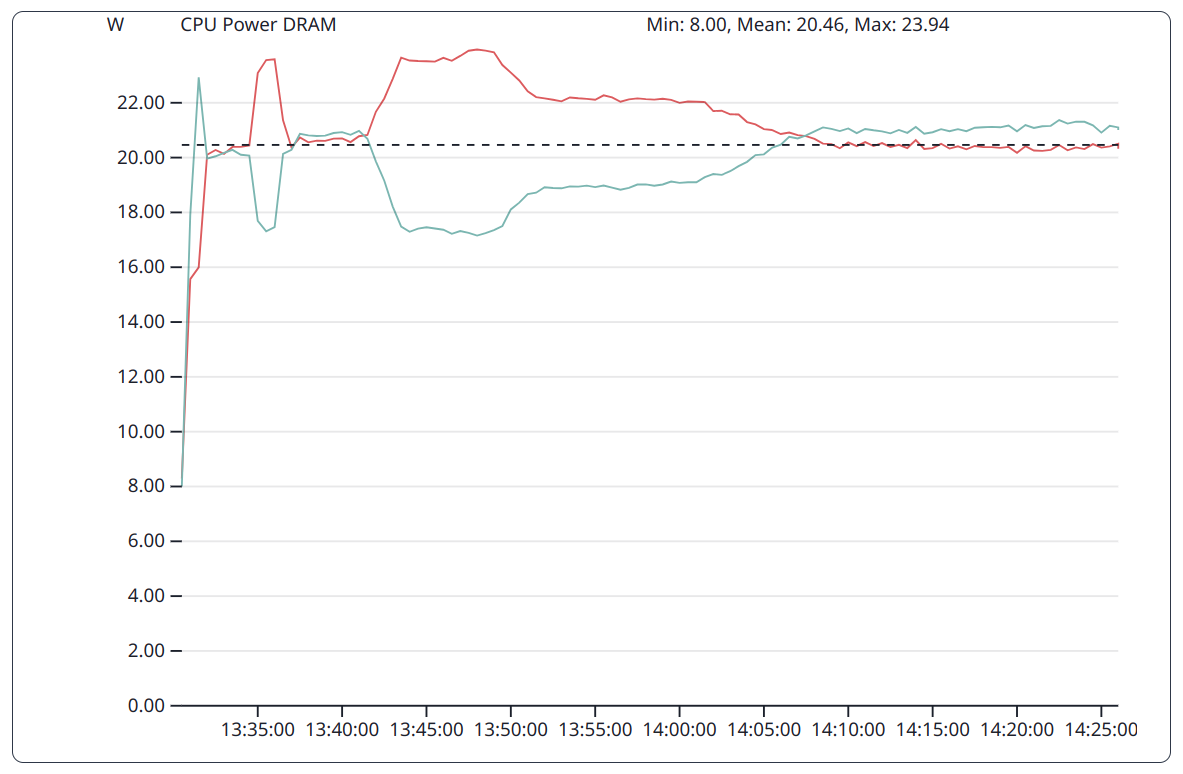
DGEMM as a compute bound benchmark does put less pressure on the DRAM subsystem. This is reflected in the varying power consumption of this subsystem over time.
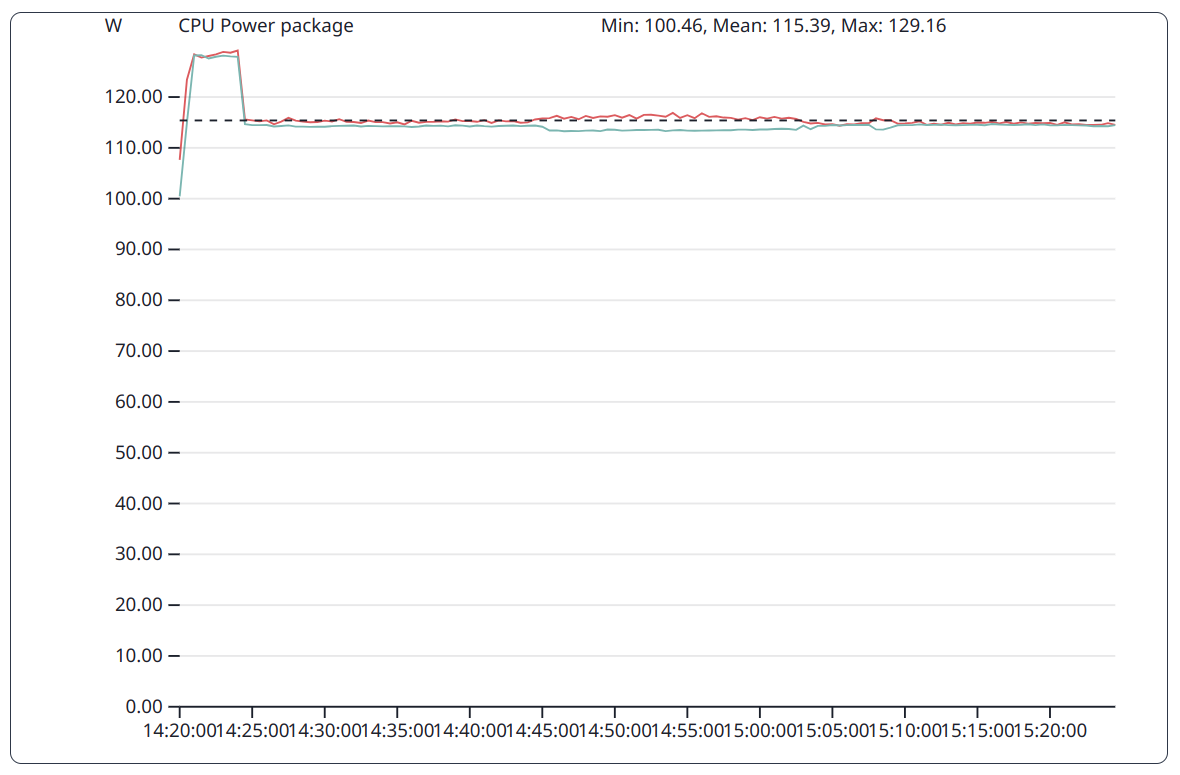
The GPU implementation of the HPCG benchmark has a preparation phase executed on the CPU and a computation phase executed on the GPU. During the first phase the power consumption of the CPU package is therefore higher than in the subsequent phase.
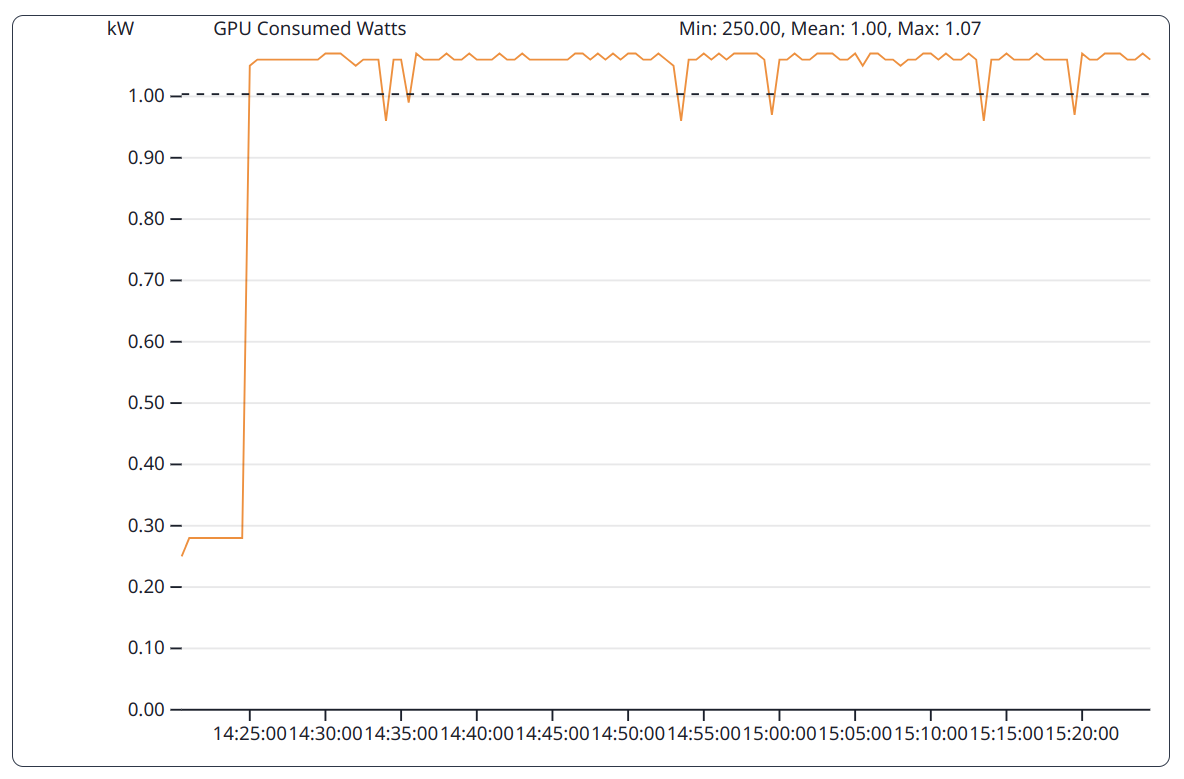
The GPU implementation of the HPCG benchmark has a preparation phase executed on the CPU and a computation phase executed on the GPU. During the first phase the power consumption of the GPUs is therefore lower than in the subsequent phase.
Filesystem¶
This category offers the following diagrams for Home and Workspace filesystems:
- I/O operations/s (reads and writes)
- Throughput/s (bytes read/written)
- Metadata operations/s
Examples: Category Filesystem
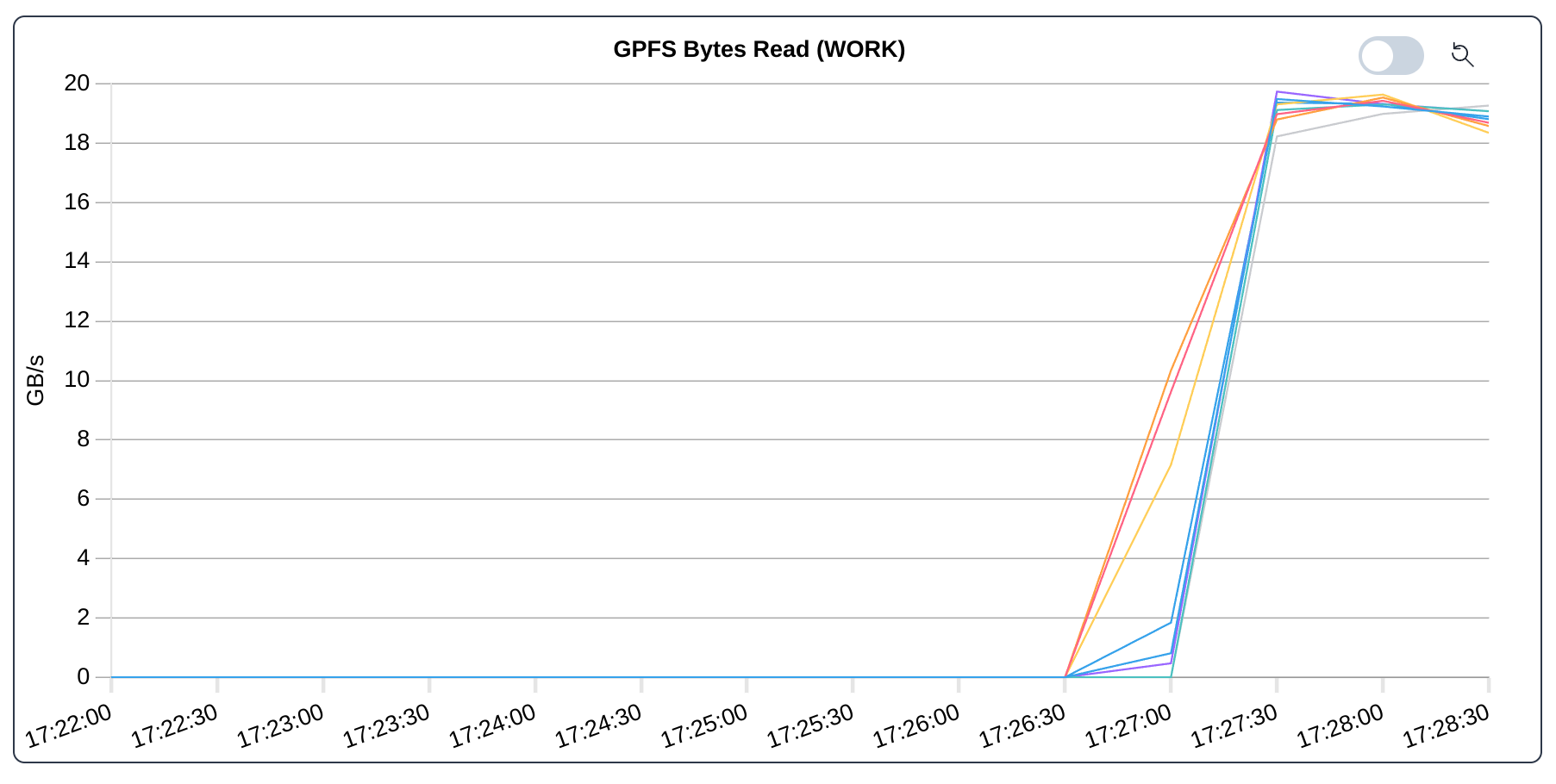
Bytes read for the IOR benchmark.
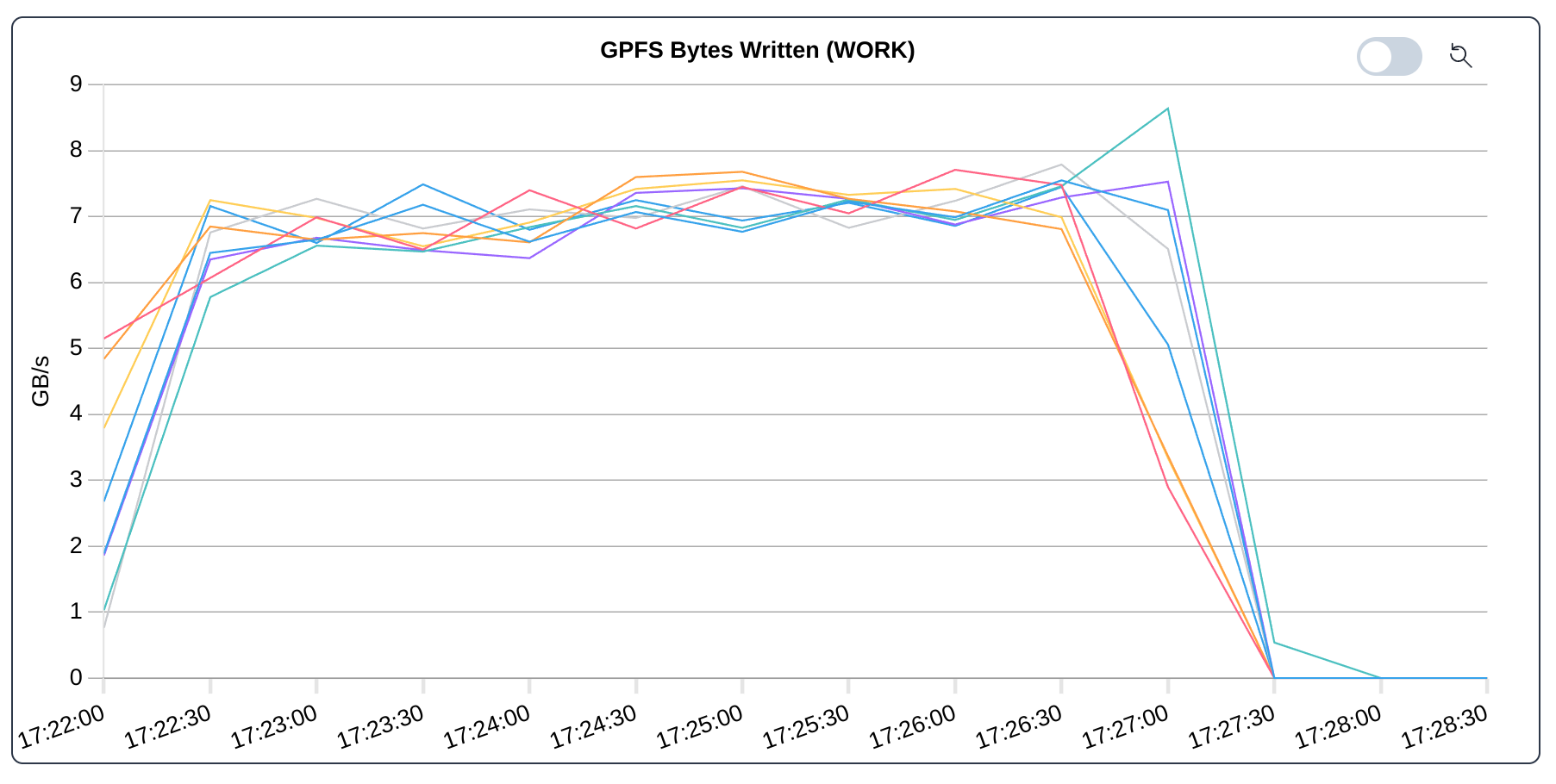
Bytes written for the IOR benchmark.
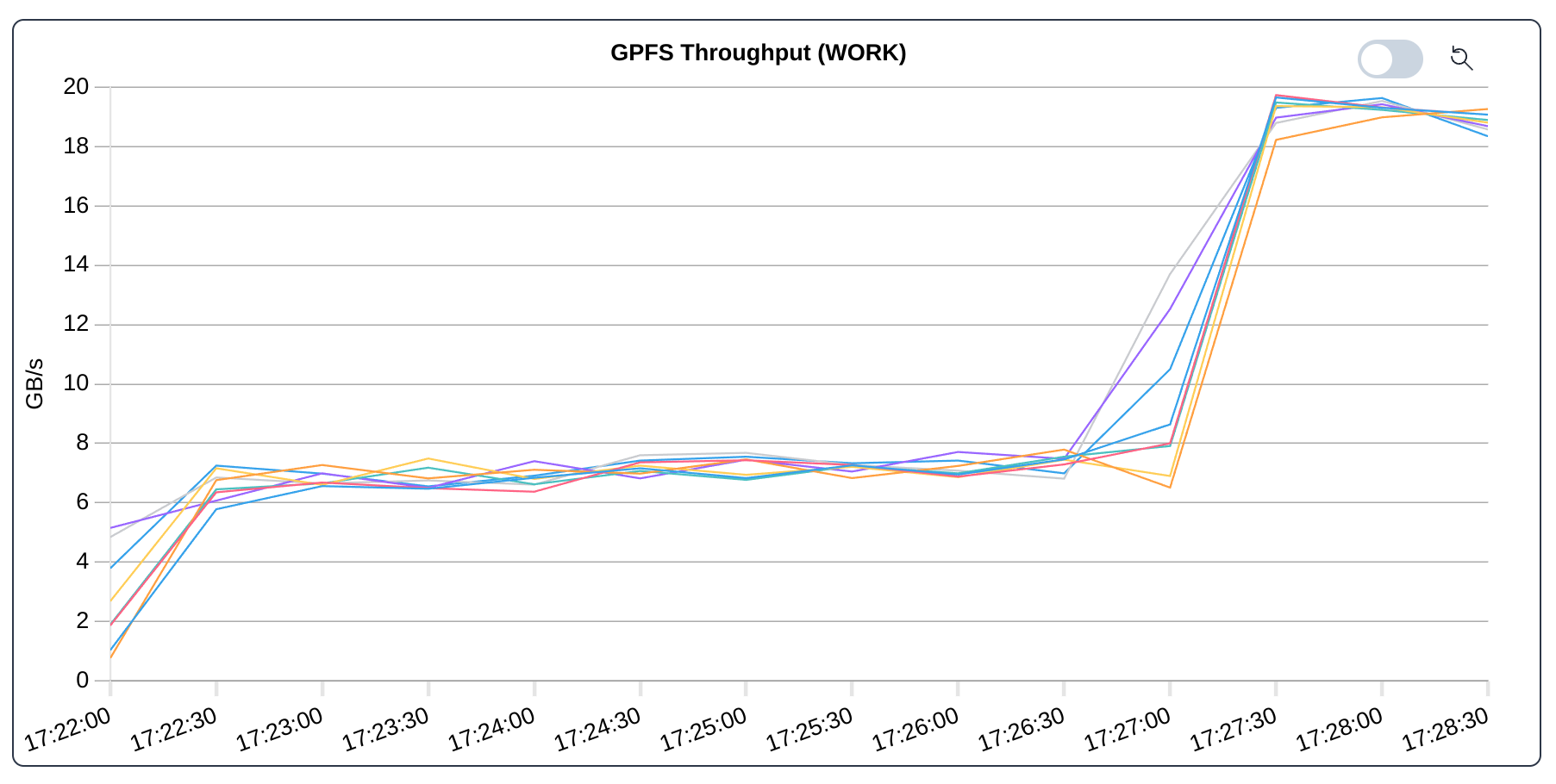
Total throughput for the IOR benchmark
Interconnect¶
This category offers diagrams for:
- InfiniBand: Send, receive and aggregated bandwidth
- InfiniBand: Send, received and aggregated number of packets
Examples: Category Interconnect

InfiniBand send bandwidth for OSU Micro-Benchmark. In the point to point communication node hkn0201 sends data while node hkn0202 only receives data (send bandwidth is zero).
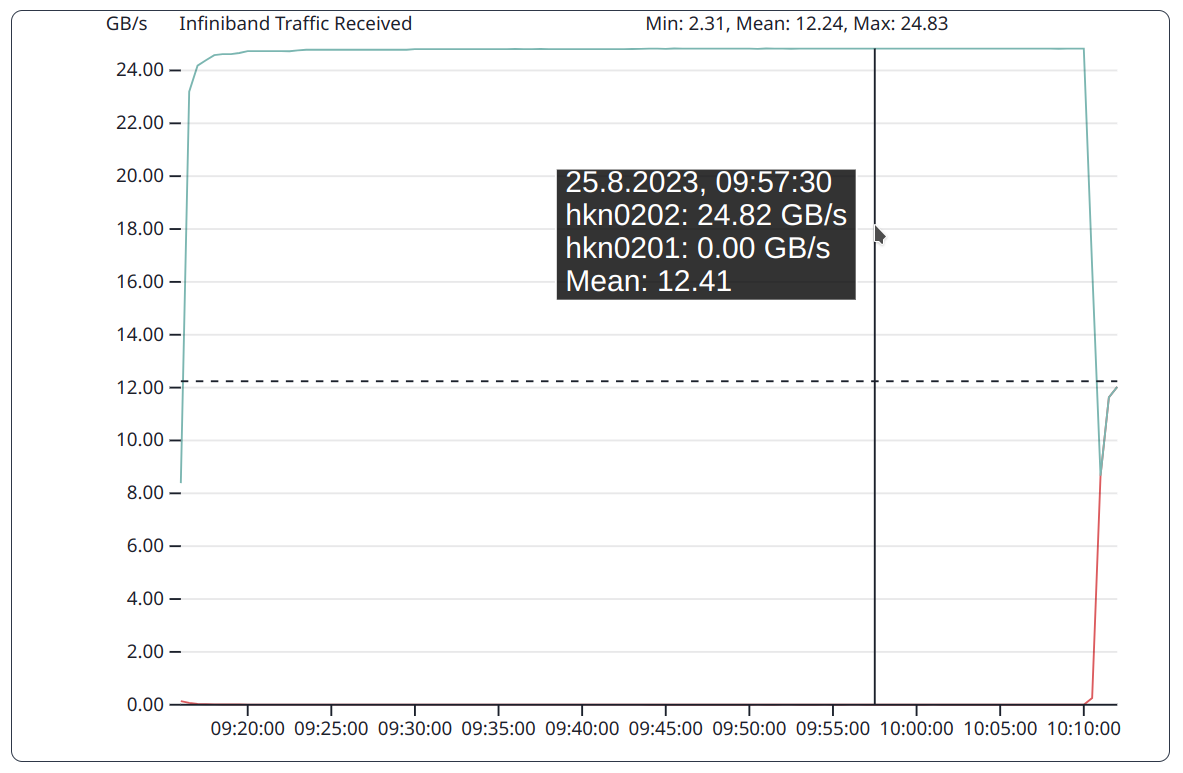
InfiniBand receive bandwidth for OSU Micro-Benchmark. In the point to point communication node hkn0202 receives data while node hkn0201 only sends data (receive bandwidth is zero).
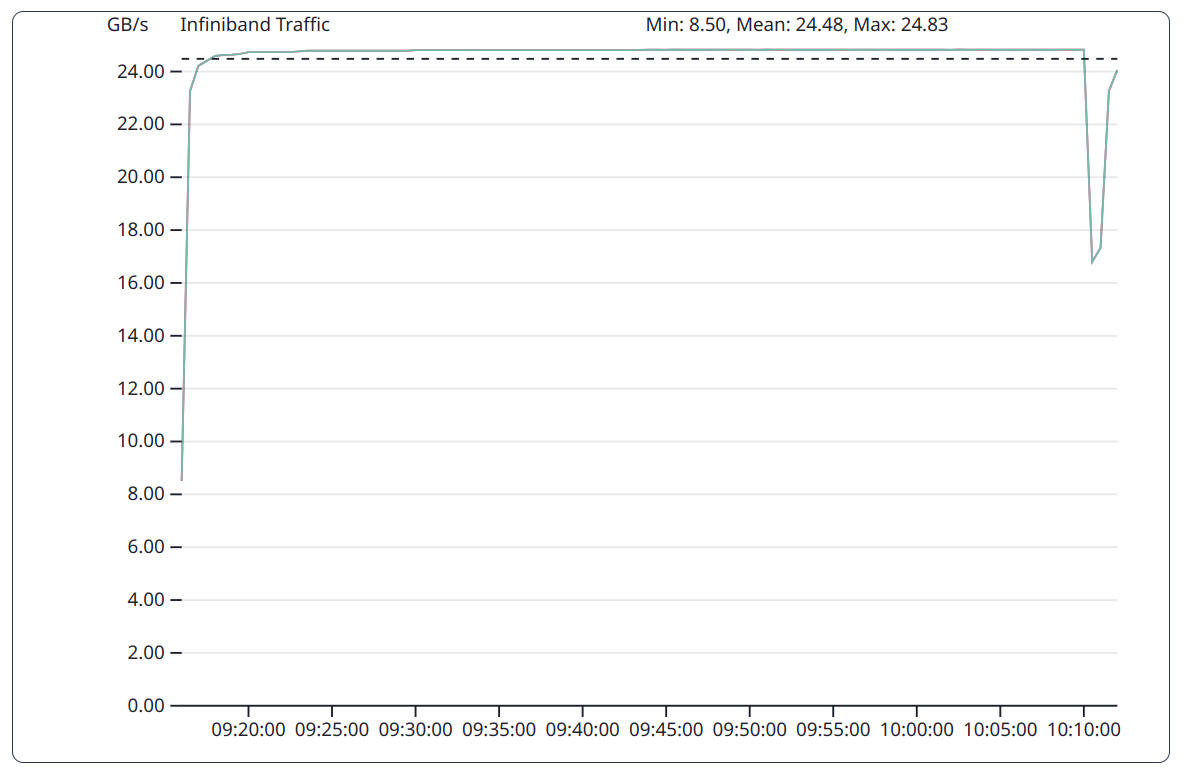
InfiniBand bandwidth for OSU Micro-Benchmark. In the point-to-point communication, both nodes use the same bandwidth, even though one of the nodes only sends data and the other one only receives data.
Memory¶
This category offers diagrams for:
- Amount of memory used on the system (CPU) and on the GPU
- CPU memory bandwidth
- GPU memory utilization (in %) and frequency
Examples: Category Memory
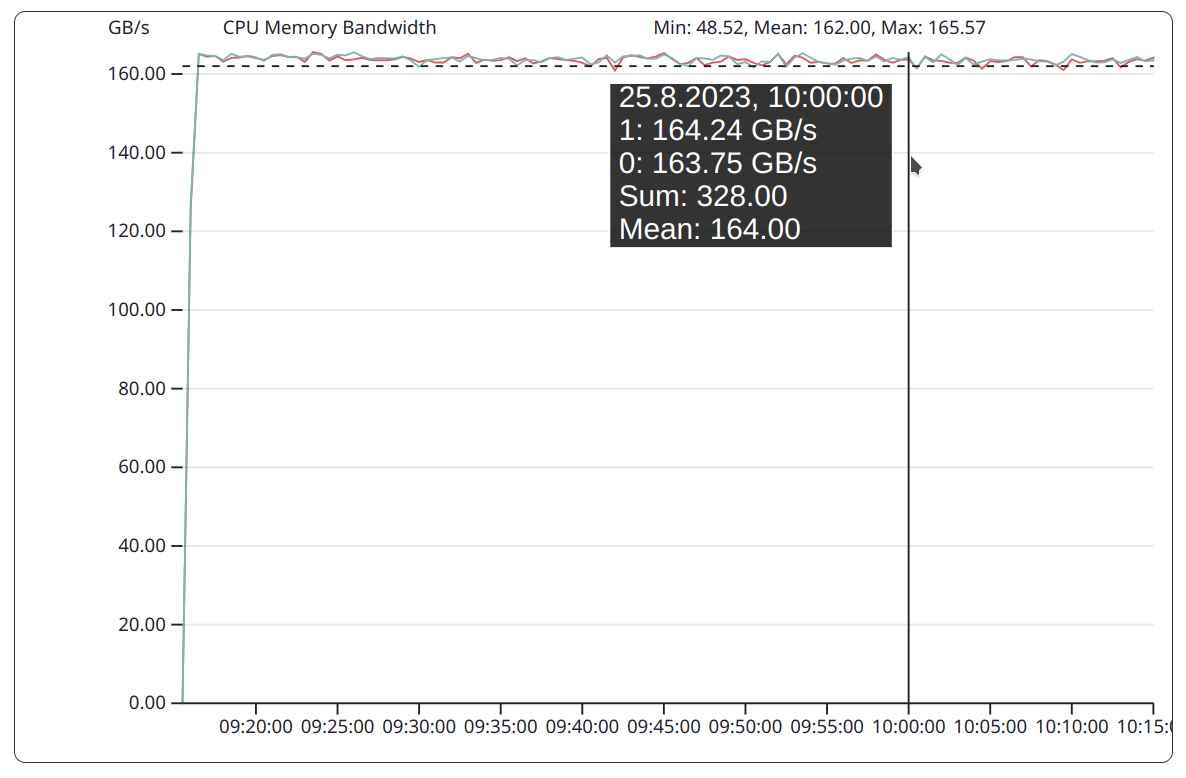
Stream as a memory bound benchmark put constantly high pressure on the memory subsystem.
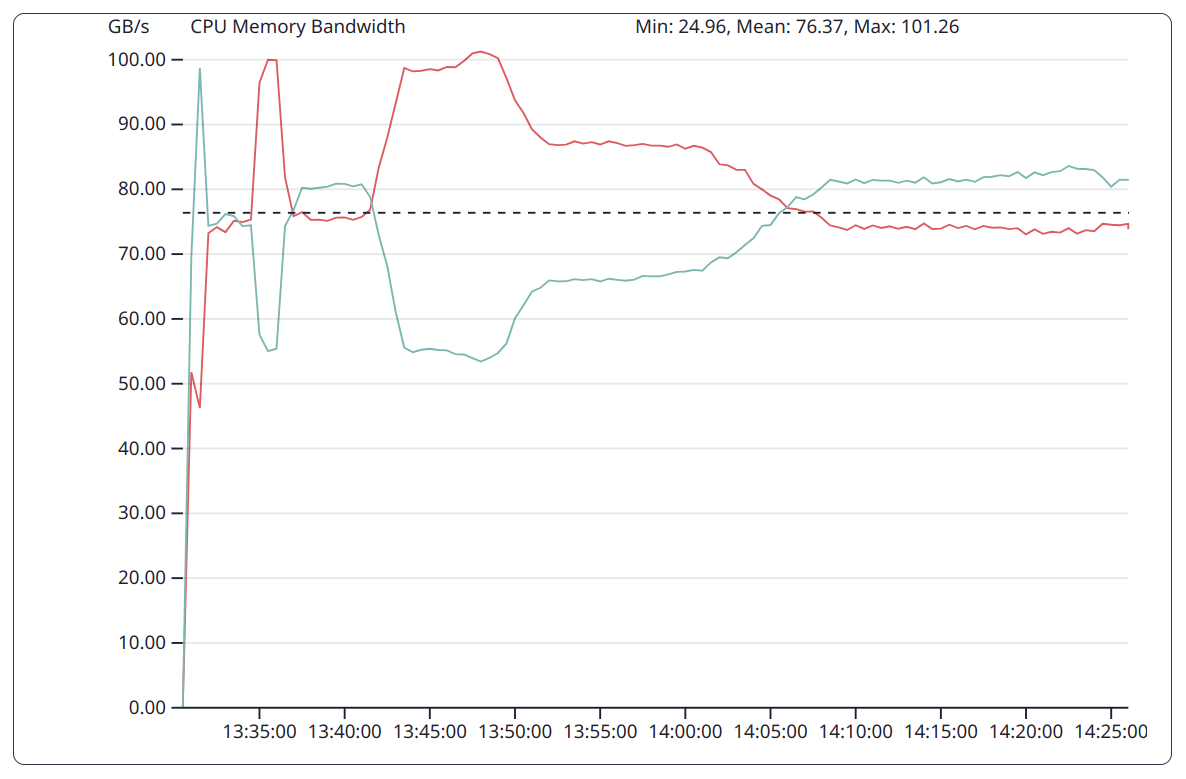
DGEMM as a compute bound benchmark does put less pressure on the memory subsystem. This is reflected in the varying bandwidth over time.
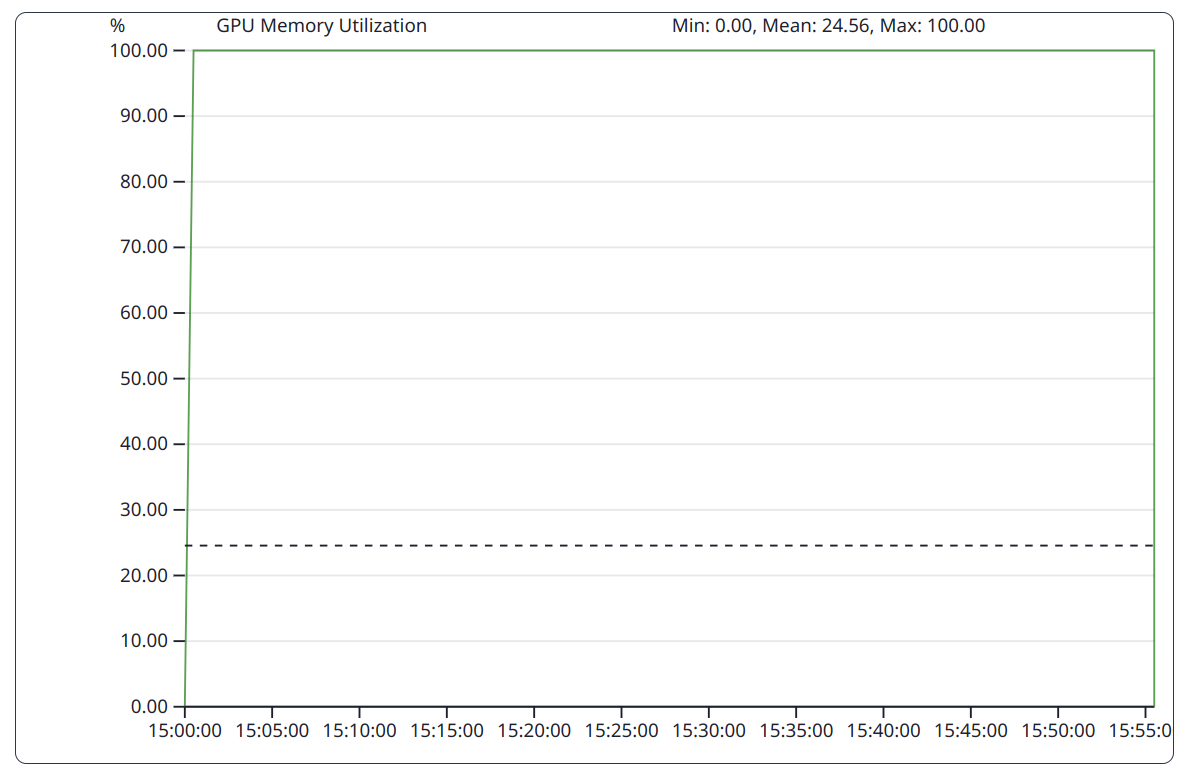
Babelstream as a memory bound benchmark fully utilizes the memory subsystem of the GPU.
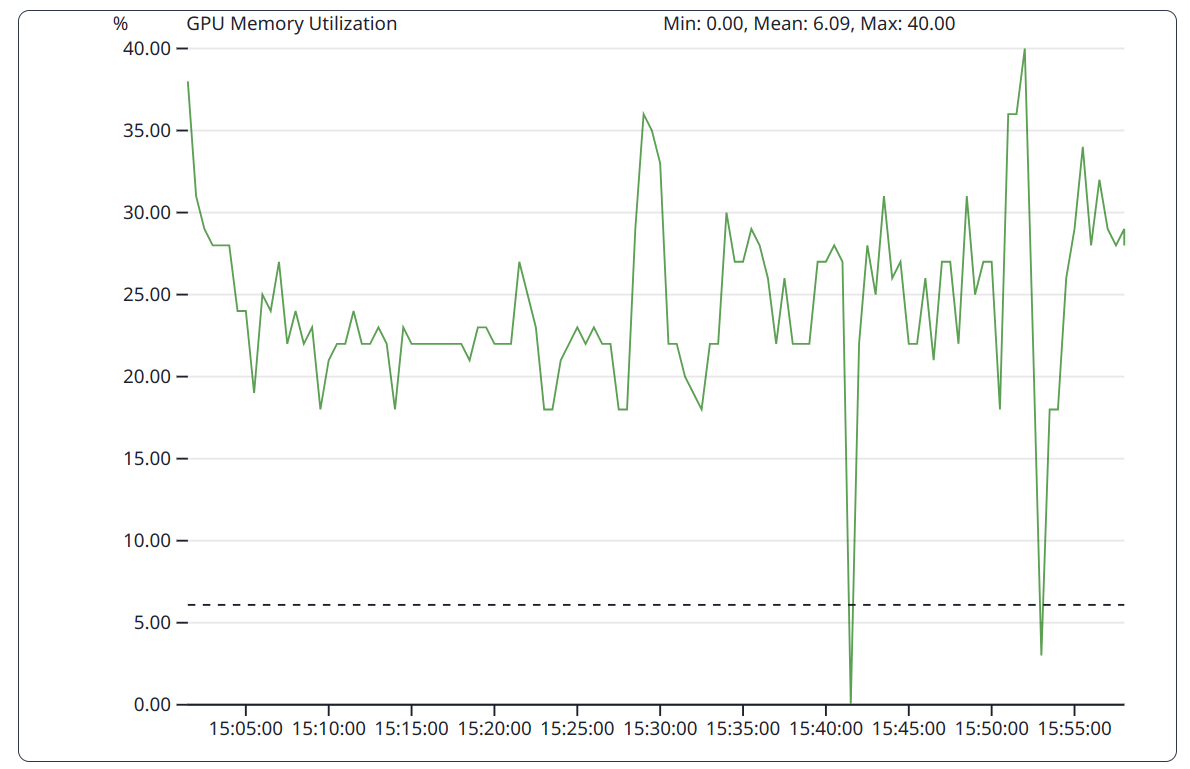
The GPU implementation of DGEMM as a compute bound benchmark does put less pressure on the GPU memory subsystem. This is reflected in the varying utilization over time.
Performance¶
This category offers diagrams for:
- Floating point operation per second (FLOPs), collected per hardware thread and aggregated per core or per socket
- Instructions per cycle (IPC), collected per hardware thread and aggregated per core or per socket
- CPU time spent in kernel and in user space
- One Minute Linux load average
- GPU utilization
- CPU and GPU frequency
Examples: Category Performance
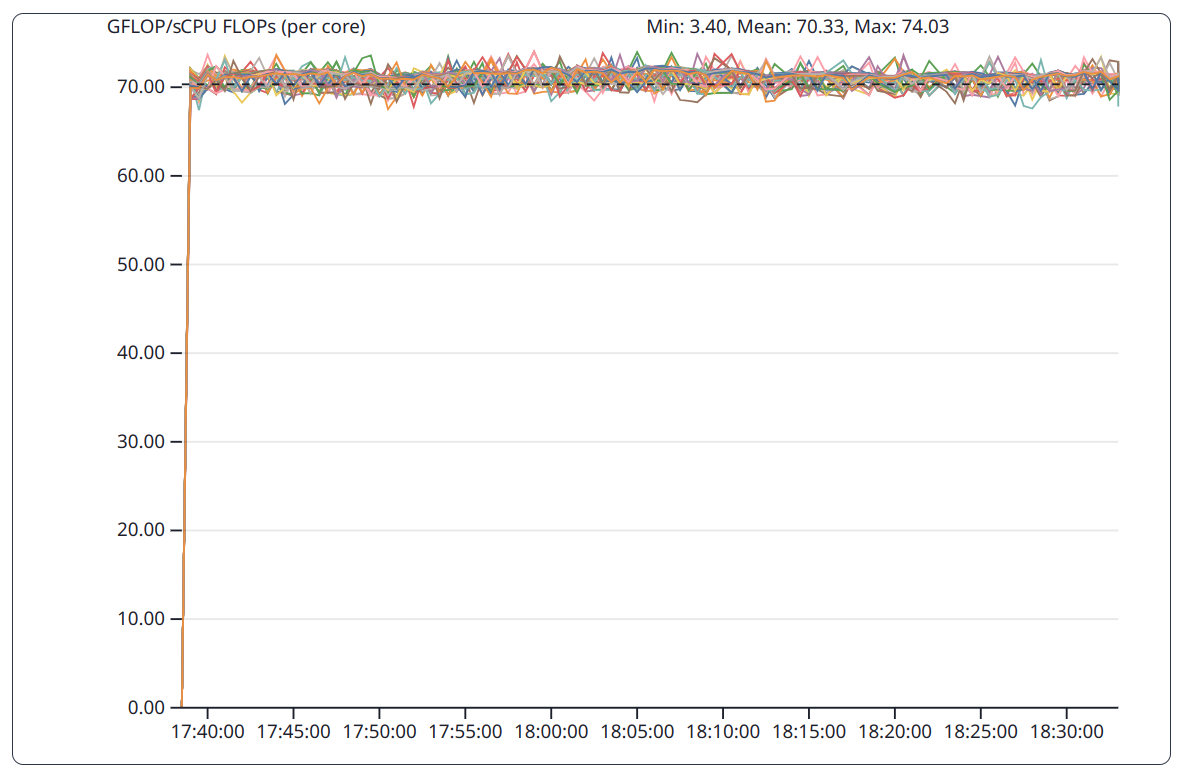
Floating point operation per second (FLOP/s) are collected per hardware thread. As hardware threads of a core share the same compute units it may be more appropriate to aggregate per core.
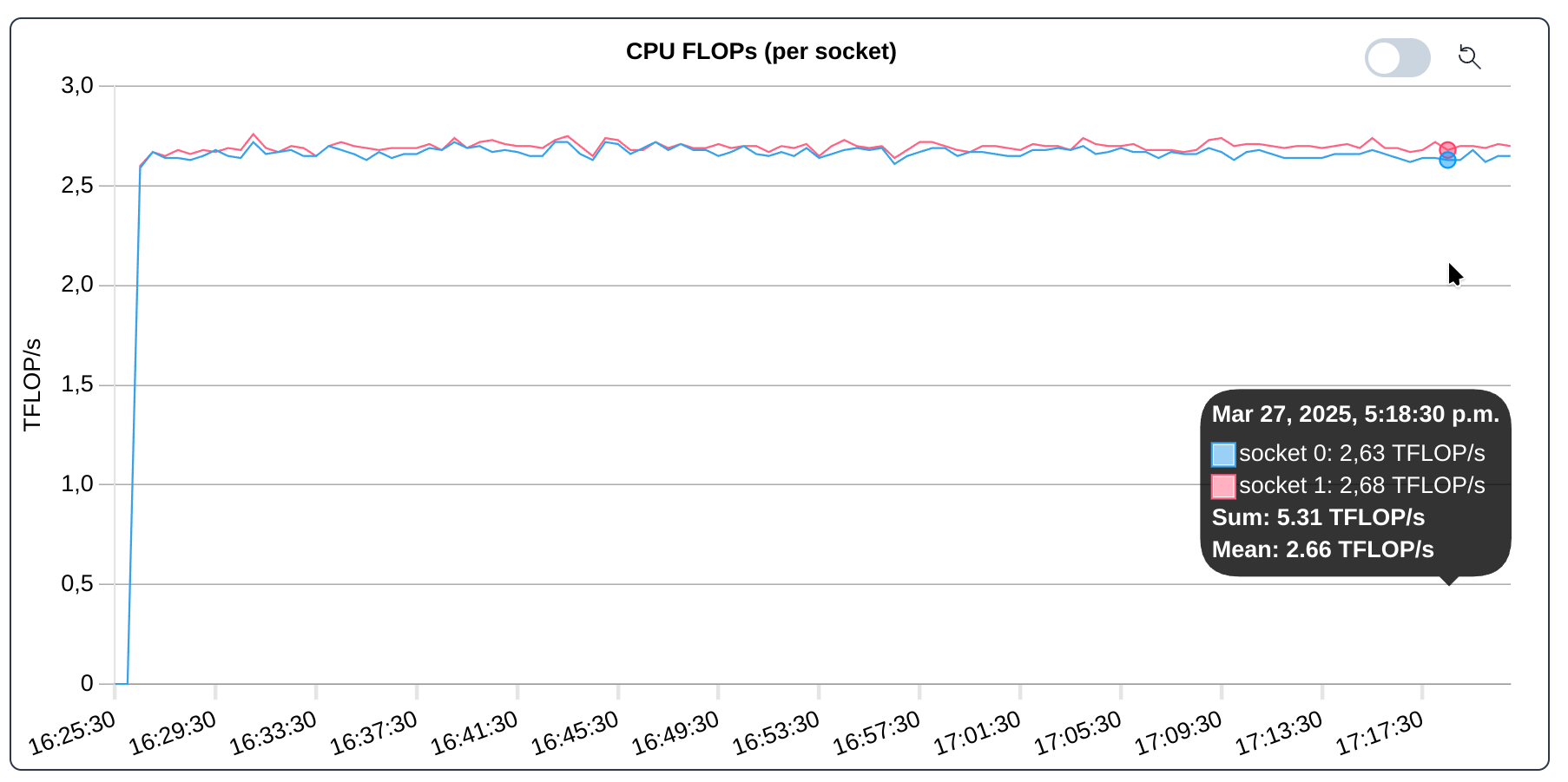
Floating point operation per second (FLOP/s) are collected per hardware thread. To examine the even utilization of the CPU sockets, an aggregation per socket can be beneficial.
Temperature¶
This category offers diagrams for:
- CPU and GPU temperature
Examples: Category Temperature
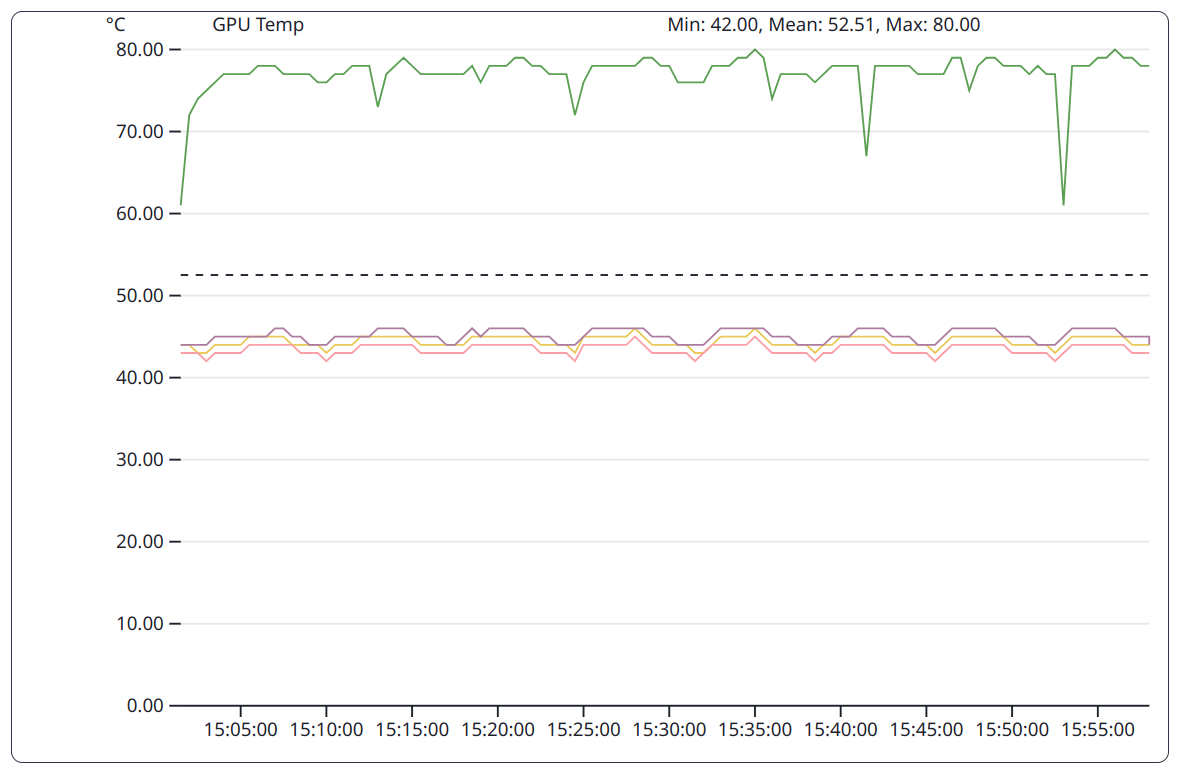
The GPU implementation of the DGEMM benchmark only utilizes one of the GPUs. Only this GPU gets hot, while the other GPUs maintain a lower temperature.
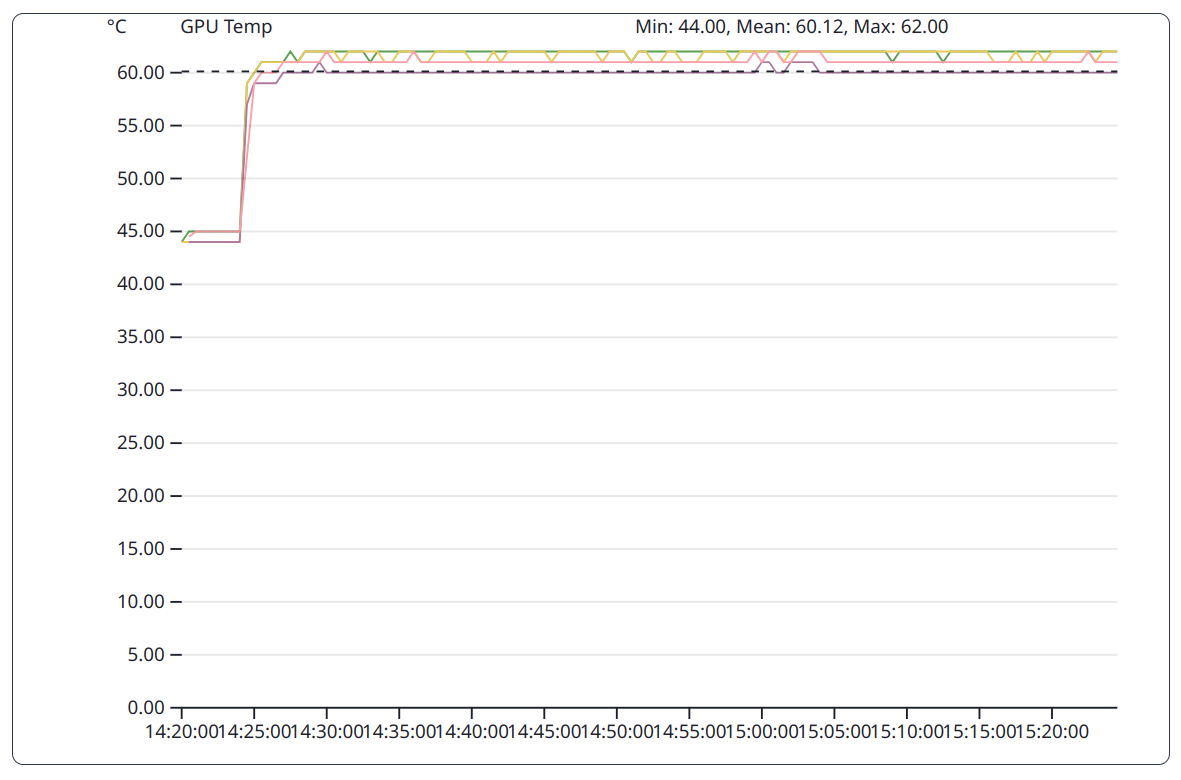
The GPU implementation of the HPCG benchmark has a preparation phase executed on the CPU and a computation phase executed on the GPU. During the first phase, the GPU is not utilized and therefore stays cooler than in the subsequent phase.
Additional Features¶
- For multi-node jobs, there is a configuration option to select the per-node aggregation function used (e.g. average, sum, maximum)
- Live view of still running jobs
- Export metrics for offline analysis
- Favorite metric category
- The default category is Performance. You can change it using the star button.
- Metric analyzers:
- Changepoint analyzer: A heuristic analyzer that marks times where metric behavior changes.
- I/O analyzer: Analyzes I/O metrics by comparing the mean rate and the final sum against predefined threshold values. If thresholds are exceeded, tags are applied.
- Roofline chart
Changepoint metrics
To avoid excessive load on our time-series database. The change points are computed only for a subset of metrics select by admins. The sample rate at which they're computed is also chosen automatically.
Performance tips¶
-
Filter out metrics that are not relevant to your analysis. This makes a significant difference for categories with many metrics.
-
Choose a favorite category to avoid fetching and rendering metrics you are not interested in.
-
JobMon selects a sample rate automatically (typically the coarsest interval). Choosing a very small sample interval can significantly increase loading time and may cause requests to time out; in that case, no data will be displayed.